요즘 프롬프트에 관심이 생겼고 이 논문이 관심이 가게 되어서 리뷰를 하게 되었다.
ProQA: Structural Prompt-based Pre-training for Unified Question Answering
https://aclanthology.org/2022.naacl-main.313/
Introduction
질의응답(QA, Question Answering)은 NLP 연구에서 오랫동안 영감을 주는 도전과제로 여겨져 왔다. 최근 연구에서 모델은 특정 질문 유형(Extractive QA, Abstractive QA, Multiple-Choice QA)이나 특정 분야(NewsQA, NaturalQA)에 초점에 맞춰져 있다.
최근 LLM에 대한 연구는 다양한 Task에 대해 연결성이 있을 수 있음을 시사하며 이 논문에서는 Task 간의 연결성을 모델링하기 위해 다양한 QA Task를 하나의 모델에서 해결할 수 있는 통합 패러다임인 ProQA를 제시한다.
ProQA : 두 가지를 모델링할 수 있다.
- 일반적으로 요구되는 QA 능력
- 동일한 패러다임에서 여러 QA Task 간 공통성과 차이점 모델링
2가지 모델링을 위해 2가지 문제를 직면한다.
- 다양한 Domain/Format 에서 QA task 간 공통점을 모델링하고 전이성을 강화하며 충돌을 피하는 방법
- Pre-training을 위한 High-Quality QA Data의 부족에 대해 Large-scale QA Corpus 생성 방법
→ 두 가지 문제를 해결하기 위해 Structural prompt, Structural prompt-based pre-training와 대규모 합성 QA 코퍼스 구축을 통해 ProQA : 통합 QA 패러다임을 구상한다.
AboutQA
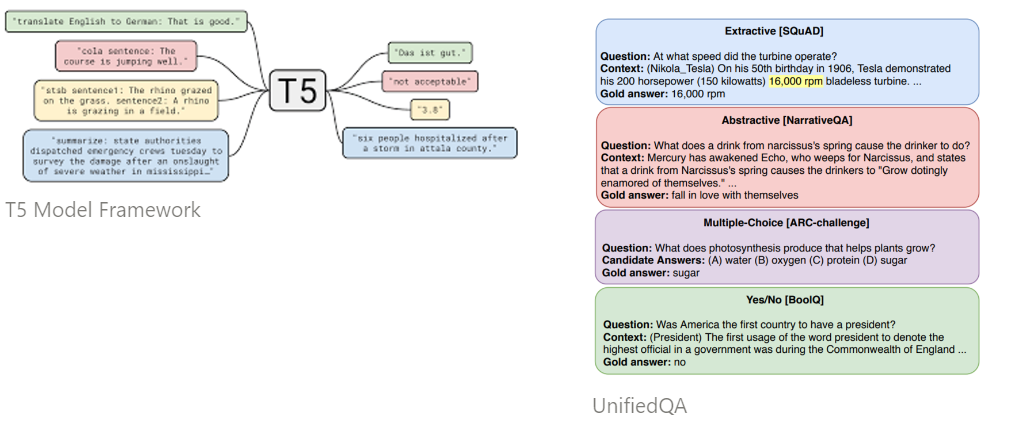
논문에서는 UnifiedQA와 T5(Text-to-Text Transfer-Transformer의 영감을 받아, Downstream QA Task에서 통합 Text-to-Text 모델을 사용합니다. 이 작업에서는 T5 모델을 백본으로 사용합니다.

위의 그림을 보게되면, 다양한 QA 작업을 위해 통합된 Structural prompt로 구성됩니다. 또한, QA 능력과 Structural prompt의 의미와 Task 간의 공통점과 차이점을 학습하기 위해 Structural prompt-based pre-training을 진행합니다.
Structural Prompt

위의 Structural Prompt는 여러 개의 { Key : Value }로 구성됩니다.
- KEY
- Key indicator : [ ]
- 구성 요소간의 기능적 차이를 구별하여 모델을 강화하기 위해, 각 키를 학습 가능한 표현을 가진 특별한 Key indicator을 사용합니다.
- e.g., $Task, Format, Question,\space etc.$
- Key indicator : [ ]
- Value : 두 가지로 표현합니다.
- textual content of the data instance (데이터 인스턴스의 텍스트 내용)
- e.g., $question,\space passage,\space options$
- the combination of a discrete $hard\space prompt$ and $soft\space prompts$
- Hard prompt (< >) : 미리 정의된 이산적인 설명 (특수 토큰을 사용)
- e.g,. Extrative QA, Abstractive QA와 같이 첫 번째 그림의 여러 요소들
- Soft prompt (Grey squares) : 학습 가능하고 플러그 앤 플레이가 가능한 연속 임베딩
- 여러 Task/Domain/Format의 차이를 모델링하기 위해, Customized characteristics를 나타내는 학습 가능하고 저장 가능한 Soft prompt를 사용
- Hard prompt (< >) : 미리 정의된 이산적인 설명 (특수 토큰을 사용)
- textual content of the data instance (데이터 인스턴스의 텍스트 내용)
Structural Prompt = { (Key indicator : Hard Prompt or Soft Prompt) * $k$ }
Key Indicator : 구성 요소 간의 기능적 차이를 구별하는 데 사용
Hard Prompt : Task를 구별하는 역할
Soft Prompt : 여러 Task/Domain/Format간 차이와 공통점등을 모델링할 때 사용하며 이 Soft prompt는 학습가능하며 저장 가능하다.
입력 표현
구조적 프롬프트 형식의 인스턴스가 주어지면, 모델 입력으로 변환한다.
$k$번째 키를 $key\space indicator\space D_k$로 변환하고, 특정 값의 토큰 $V_k$에 의해 토큰 시퀀스를 형성하며, $E_k\space = \space Embedding([D_k;V_k])$로 표현한다. $D_k$의 표현은 훈련 중에 초기화되고 업데이트됩니다.
소프트 프롬프트인 Task/Format/Domain를 값으로 $P_{task}/P_{format}/P_{domain}$를 사용하고 편의를 위해 먼저 추가하고 모든 $E_k$를 연결하여 입력 $X$를 만든다.
$X = [P_{domain};P_{format};P_{task};E_1;...;E_k]$
Key indicator D와 Soft prompt P는 Pre-training 중에 공동으로 훈련되며, Structrual prompt의 의미를 학습한다. 다양한 작업에 조정된 후, Soft prompt P는 customized 작업별 특성을 기록하기 위해 저장될 수 있다.
Structural Prompt-based pre-training
Task Formulation
이 부분에서는 모델이 Pre-training 중에 요구되는 QA 능력과 Structrual prompt의 의미를 학습하는데 도움이 되는 Structural prompt-based pre-training이 수행되는 방법에 대해 소개합니다.
Pre-training을 위한 다양한 QA 유형(i.e., $Extractive\space QA,\space Abstractive\space QA,\space Multiple-choice QA$)을 제시하며, QA 능력을 주입한다. Multi-format QA corpus가 주어지면, 제안된 Structural prompt에 따라 QA 형식으로 변환하여, 형식 간의 차이를 유지하면서 공동으로 Pre-training을 가능하게 합니다.
→ Structural prompt로 Instance를 형식화해 입력으로 바꾼 뒤, 자유 형식의 답변을 출력하여 작업은 QA 작업으로 더 맞춤화됩니다.
Pre-training Corpus Construction
Pre-training을 위한 QA Corpus는 2가지 이유로 데이터 부족이 심각합니다.
- Pre-training을 위한 고품질 주석이 달린 데이터는 비현실적이며 번거롭습니다.
- 규칙 기반(token masking or sentence reordering)을 사용해 QA 중심 self-supervised 데이터 생성은 어렵습니다.
이 작업에서 Generation-filtering based corpus construction method를 채택하여 600M개의 본문을 포함한 Large-scale unlabeled Wikipedia corpus를 기반으로 Corpus를 합성합니다.
과정은 다음과 같다.
- QA 쌍 생성 모델 $g_{qa}(q,a|c)$ : 본문 $c$ 를 입력으로 사용할 때, $g_{qa}(q, a|c)$는 질문 q와 그 답변 $a$를 포함하는 출력 시퀀스 $q$ [SEP] $a$를 생성한다.
- 생성된 QA 쌍을 필터링하여 질문과 답변의 품질과 일관성을 보장하기 위한 필터링 QA 언어 모델 f(a|q, c)는 조건부 확률 기반 접근 방식을 사용하여 QA 쌍을 부드럽게 필터링합니다. 이는 본문 c c와 질문 q에 대한 답변 a의 가능성으로 QA 쌍 (q, a)을 평가합니다. 점수가 임계값보다 높은 QA 쌍은 사전 훈련을 위해 보존됩니다.
Experimental Setup
실험에서는 세 가지 형태의 QA Dataset을 고려합니다. Extractive QA, Abstractive QA, MultiChoice QA
11개의 Dataset은 3가지 형식과 다양한 언어 이해 능력을 갖고 있습니다.
| Format | Dataset | QA Skills | Metrics |
| Extractive QA | SQuAD | Word Matching | EM(Exact Match) |
| Extractive QA | Quoref | Coreference Reasoning | EM(Exact Match) |
| Extractive QA | NewsQA | Word Matching | EM(Exact Match) |
| Abstractive QA | NarQA | Story Understanding | ROUEL-L |
| Abstractive QA | DROP | Discrete Reasoning | F1 |
| Abstractive QA | NQOpen | Multi-passage Understanding | F1 |
| MultiChoice QA | RACE | Multi-setnence Reasoning | Acc |
| MultiChoice QA | DREAM | Dialog Reasoning | Acc |
| MultiChoice QA | MCTest | Multi-setnence Reasoning | Acc |
| MultiChoice QA | OBQA | Common knowledge | Acc |
| MultiChoice QA | SIQA | Commonseense Reasoning | Acc |
Results and Analyses
Main Results
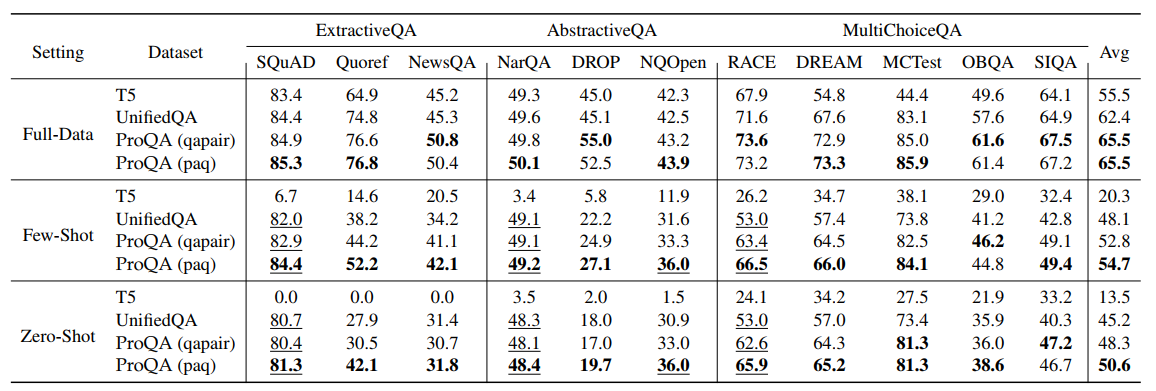
- QA 중심 사전 훈련 모델인 UnifiedQA와 ProQA는 시드 데이터셋과 비시드 데이터셋 모두에서 T5를 큰 차이로 능가한다. 다양한 QA 작업 간 전이 가능한 지식이 있기 때문입니다.
- ProQA는 UnifiedQA보다 Few-Shot 및 Zero-Shot에서 UnifiedQA를 큰 차이로 이깁니다.
- Structural prompt 내의 hard prompt와 soft prompt가 QA 작업에 대해 지시 Customization을 가능하게 하며 특히 “Task”의 key-value쌍이 중요합니다.
- Structural prompt-based pre-training은 비시드 데이터에 더 빠르고 잘 적응할 수 있도록 도와줍니다.
- proQA(qapair)과 ProQA(paq)에서 paq가 우수한 성능을 보인다. 이 방식으로 데이터 생성을 하려면 네 개의 BERT 모델이 준비되어야 하지만, 논문에서의 qapair은 단순하며 모델을 하나를 사용하며 3개의 QA Corpus 추출에 적용할 수 있습니다.
Ablation Study
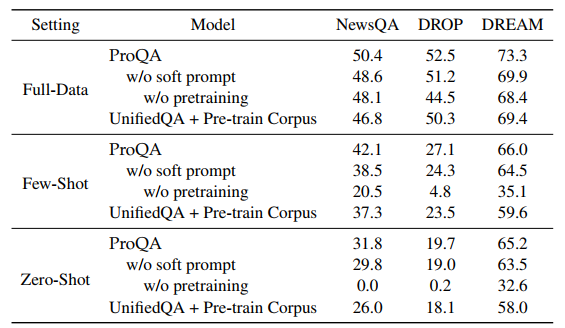
각 구성 요소의 효과를 밝히기 위한 소거 연구가 수행되었습니다. 총 3가지 변형을 고려했습니다.
- Soft prompt를 제거한 ProQA
- 추가적으로 pre-training을 제거한 ProQA
- UnifiedQA + Pre-trained Corpus는 논문에서 준비한 합성 QA 코퍼스로 Pre-trained 모델
3가지를 통해 모델에서 Soft prompt를 제거하면 Pre-training도중에 학습된 작업별 지식이 비활성화된다는 것입니다. Prompt-based pre-training을 제거하면, 성능이 크게 떨어지며 동등한 모델인 (T5 + hard structural prompt)에는 어떠한 QA 지식도 없기 때문입니다.
→ UnifiedQA + Pre-train Corpus는 ProQA보다 낮은 성능을 나타내며, 논문에서 제시한 Structral prompt가 지식 Generation와 지식 Customization 사이의 더 나은 균형을 보여줍니다.
출처
ProQA : https://aclanthology.org/2022.naacl-main.313/
UnifiedQA : https://arxiv.org/abs/2005.00700
T5 : https://arxiv.org/abs/1910.10683