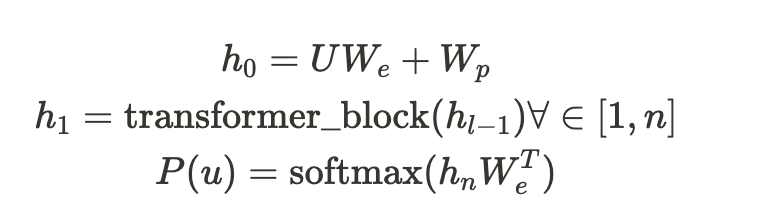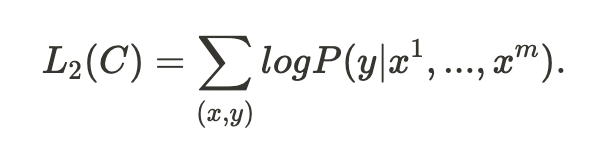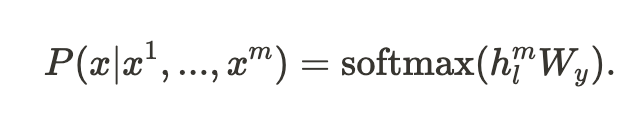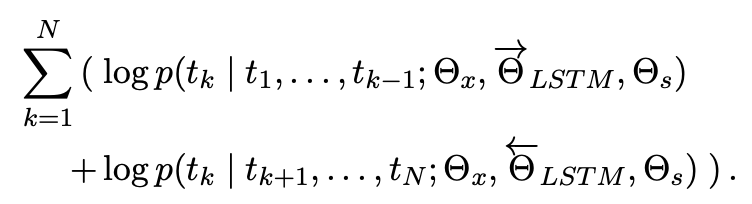정확성 : 알고리즘은 주어진 입력에 대해 올바른 해를 주어야 한다. 즉, 모든 입력에 대해 올바른 답을 출력해야 한다.
수행성 : 알고리즘의 각 단계는 컴퓨터에서 수행이 가능하여야 한다. 애매모호한 표현을 사용하면 안된다.
유한성 : 알고리즘은 유한 시간 내에 종료되어야 한다. 매우 오래 걸리면 알고리즘의 가치를 잃는다.
효율성 : 알고리즘은 효율적일수록 그 가치가 높아진다. 항상 시간적, 공간적인 효율성을 갖도록 고안되어야 한다.
2. 알고리즘의 표현 방법
2-1. 말로 표현된 알고리즘
첫 카드의 숫자를 읽고 기억한다.
다음 카드의 숫자를 읽고, 기억한 숫자와 비교한다.
비교 후 큰 숫자를 기억한다.
다음에 읽을 카드가 있으면 line 2로 간다.
기억한 숫자가 최대 숫자다.
2-2. 의사 코드(pseudo code)로 표현된 알고리즘
max = A[0]
for i = 1 to 9
if (A[i] > max) max = A[i]
return max
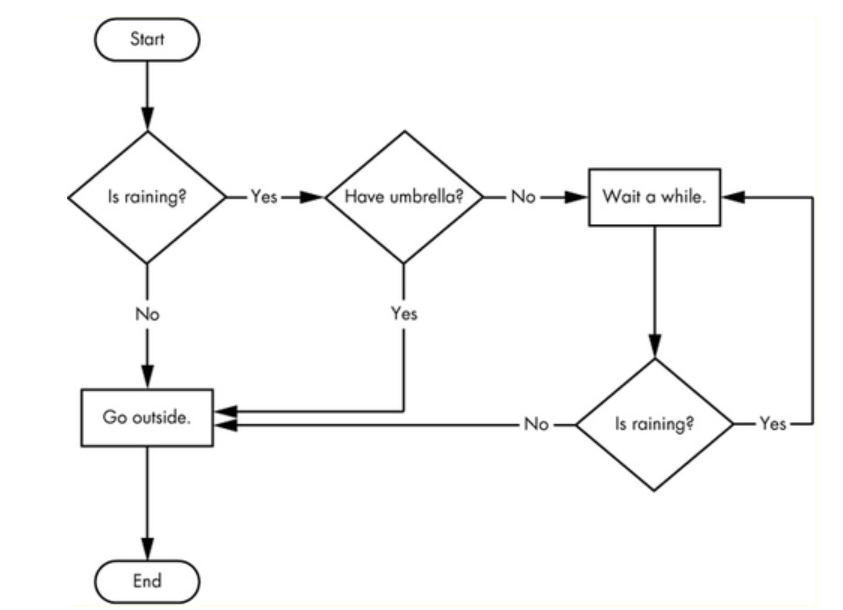
2-3. 플로차트(flow chart)로 표현된 알고리즘
매우 제한적으로 사용
3. 알고리즘의 효율성 표현
알고리즘의 수행 시간 또는 알고리즘이 수행하는 동안 사용 되는 메모리 공간의 크기로 나타낼 수 있다. 이들을 각각 시간복잡도(time complexity), 공간복잡도(space complexity)라고 한다. 일반적으로 알고리즘들을 비교할 때에는 시간복잡도가 주로 사용된다.
컴퓨터에서 수행된 시간을 측정할 수 있지만, 실제 측정된 시간은 여러 가지 변수가 있다.(컴퓨터의 성능, 프로그래밍의 언어, 최적화 등등) 따라서, 알고리즘이 수행하는 기본적인 연산 횟수를 입력 크기에 대한 함수로 표현한다.
예를 들어, 10장의 숫자 카드에서 최대 숫자를 찾을 때, 비교연산은 총 9번(n-1)이다. 따라서 시간복잡도는 (n-1)이다.
효율성 표현
공간복잡도 (space complexity) : 극히 제한적인 문제(merge sort) 같은 문제에서나 사용됨
시간복잡도 (time complexity)
최악 경우 분석 (worst case analysis) : '어떤 입력이 주어지더라도 얼마 이상을 넘지 않는다'라는 표현
평균 경우 분석 (average case analysis) : 입력이 확률 분포가 균등 분포 (uniform distribution)이라 가정한다. 즉, 입력이 무작위로 주어진다고 가정한다.
최선 경우 분석 (best case analysis) : 최적(optimal) 알고리즘을 고안하는데 참고 자료로 활용 즉, 이보다 성능이 우수한 알고리즘은 없다.
4. 복잡도의 표기
시간(또는 공간) 복잡도는 입력 크기에 대한 함수로 표기, 주로 여러 개의 항을 가지는 다항식이다. 이를 단순한 함수로 표현하기 위해 점근적 표기(asymptotic notation)를 사용한다. 이는 입력 크기 n이 무한대로 커질 때의 복잡도를 간단히 표현하기 위해 사용하는 표기법이다.
예를 들어보자
$ 3n^3 -15n^2+10n-18$ 을 $n^3$으로, $2n^2-8n+3$을 $n^2$으로, $4n+6$을 $n$으로 단순화시킨다. 즉, 다항식의 최고차항만을 계수 없이 취한 것이다. 이 식에 상한, 하한, 동일한 증가율과 같은 개념을 적용하여, 점근적 표기를 사용한다.
4.1 점근적 표기
$O$(Big-Oh)-표기 : 복잡도의 점근적 상한을 나타냄
$\Omega$(Big-Omega)-표기 : 복잡도의 점근적 하한을 나타냄
$\theta$(Theta)-표기 : 복잡도의 상한과 하한이 동시에 적용됨을 나타냄
$O$(Big-Oh)-표기
O-표기는 복잡도의 점근적 상한 이라는 것을 예제를 통해 살펴보자
$f(n) = 2n^2-8+3$ 이라면, $f(n)$ 의 $O$ -표기는 $O(n^2)$이다.
-> 단순화한 함수 $n^2$에 임의의 상수 c를 곱한 $cn^2$이 $n$이 증가함에 Ekfk $f(n)$의 상한이 된다. 단, $c>0$
$O$-표기에는 c가 '숨겨져 있다'라고 생각해도 좋다.
$\Omega$(Big-Omega)-표기
$\Omega$(Big-Omega)-표기는 점근적 하한이라는 것을 예제를 통해 살펴보자
$f(n) = 2n^2-8+3$ 이라면, $f(n)$ 의 $\Omega$ -표기는 $O(n^2)$이며 '$n$이 증가함에 따라 $2n^2-8n+3$이 $cn^2$보다 작을 수 없다는 의미이다. 상수 $c$ = 1 로 놓으면 된다. 위와 마찬가지로 최고차항만 계수 없이 취하면 된다.
$\theta$(Theta)-표기
$\theta$(Theta)-표기는 복잡도가 위의 2개와 같은 경우에 사용한다. 즉, '$f(n)은 $n$이 증가함에 따라 $n^2$과 동일한 증가율을 가진다
백준 Floyd-Warshall 문제를 풀다가 시간초과가 발생했다. 시간초과 발생한 것을 보고 게시판을 찾아보면서, 내 코드와 비슷하지만, 정답을 맞은 코드를 보며 알고리즘을 비교했다. 알고리즘에는 차이가 없지만 if 문과 min 함수의 차이가 눈에 띄었다. 그리고 코드를 바꿔 풀어보면서 제목과 같은 의문을 갖게 되었다.
min 함수를 if문으로 바꿈
비교 코드
import time
if __name__ == '__main__':
sim = 10**8
s = time.time()
for _ in range(sim):
if 1 > 2:
pass
res1 = time.time()-s
s = time.time()
for _ in range(sim):
max(1, 2)
res2 = time.time()-s
print('comparison : {:.2}s, max : {:.2}s'.format(res1, res2))
* 컴파일환경에 따라 차이가 더 나거나 덜 날 수 있습니다.
위와 같은 코드를 실행하면 다음과 같은 결과를 얻을 수 있다.
2개 항을 비교할 때 max함수를 $10^8$ 번 호출과 2개 항을 비교할 때 if문 $10^8$번 한 것이다.
2개의 요소를 비교
if : 1.6s
max : 5.9s
다음과 같이 약 3배 이상의 차이를 확인할 수 있다.
이유
if문은 단 하나의 연산자 ' > '를 통해서 직관적으로 값 비교 한 번만 하면 된다.
max 함수는 max 함수라는 이름에 대한 dictionary 조회, max 함수 호출로 인하여 시간이 오래 발생한다.
하지만 위와 같은 시간은 2개의 요소를 비교할 때 이러한 현상이 발생하지만 요소의 수가 많아지다면 max 함수가 if문보다 이점이 커질 것이다.
결론
요소가 적다면 if문을 사용하고 요소가 충분히 많다면 max 함수 또는 min과 같은 함수를 사용해야 한다.
현재의 문제점은 unlabeled text corpora는 풍부하지만, 특정한 task을 위해 train data(labeled data)는 부족해 모델을 적절하게 훈련시키는 것이 현재의 문제점입니다.
저자들은 Large unlabeled text 통해 model을 generative 하게 언어 모델을 학습시키고, 특정 task에서 fine-tuning 한다면, 큰 향상을 이룰 수 있다고 말합니다.
이전 접근법과 달리, model Aritecture을 크게 수정하지 않고 fine-tuning 합니다. 이를 위해 fine-tuning 중에는 input을 변환합니다. 이러한 접근법은 밑에 보이는 NLP task에서 task만을 위해 설계된 모델들을 능가하며 12개의 task중 9개는 SOTA*를 달성했습니다.
*(state-of-the-art)
NLP tasks
1. textual entailment
2. question answering
3. semantic similarity assessment
4. document classification
etc
1. Introduction
왜 pre-training이 필요한가?
직관적으로 하나를 생각해봅시다. 수능문제를 약 1만개를 푼 한국사람과 수능문제 약 1만개를 푼미국사람이 있을 때 누가 수능 문제를 더 잘 풀 수 있을까요? 다들 생각하시겠지만 미국사람이 더 잘 풀 것이라고 생각합니다. 여기서 pre-training 과 fine-tuning 을 대입해볼 수 있습니다. pre-training은 원어를 배운 미국사람이며 나머지 fine-tuning은 수능문제 약 1만개를 푼 것이라고 볼 수 있습니다. 이를 통해 pre-training은 언어에 대해 이해도를 높이는 과정이라고 볼 수 있습니다.
대부분의 딥러닝은 Large labeling data를 필요로 합니다. 하지만, labeled data는 수동으로 만들어야 하며, 정보를 가공하는데 시간과 돈이 많이 발생하기 때문에 pre-training이 대안이 됩니다. 상당한 지도학습이 필요한 경우에도 비지도 학습으로 학습하고 지도학습을 하는 것이 성능 향상을 할 수 있습니다.
unlabeled text를 word-level 이상으로 정보를 활용하는 것이 어려운 이유
1. unlabeled text data를 효과적으로 학습하는 방법이 명확하지 않음
-> 이전 연구는 NLP 작업별로 아키텍처를 만들었고 각각의 task에서만 좋았지만 서로 다른 task에서는 좋은 성능을 나타내지 못함. 즉, 모든 것을 아우르는 좋은 접근법이 명확하지 않음
2. pre-trained model을 NLP task에 transfer 하는 가장 효과적인 방법에 대해 standard 한 것이 없음.
-> pre-trained model을 활용하는 가장 적절한 방법을 찾지 못함
이러한 점을 통해 unsupervised pre-training 과 supervised fine-tuning 을 조합한 방법을 개발하는 것이 어렵습니다. 하지만, 이 논문에서는 이 방법에 대해 탐구합니다. 방법은 2단계로 합니다.
1. unlabeled data를 통해 신경망 모델의 매개변수들을 학습시킵니다. (pre-training)
2. labeled data를 통해 supervised learning하여 task를 위한 매개변수들을 다시 학습시킵니다. (fine-tuning)
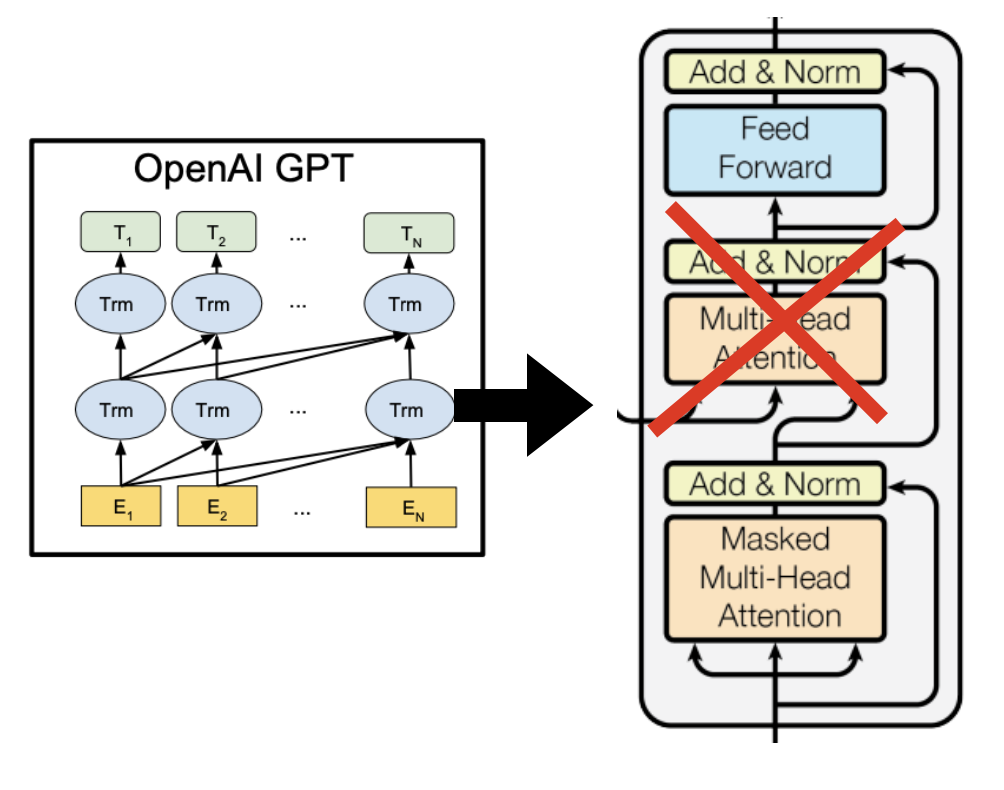
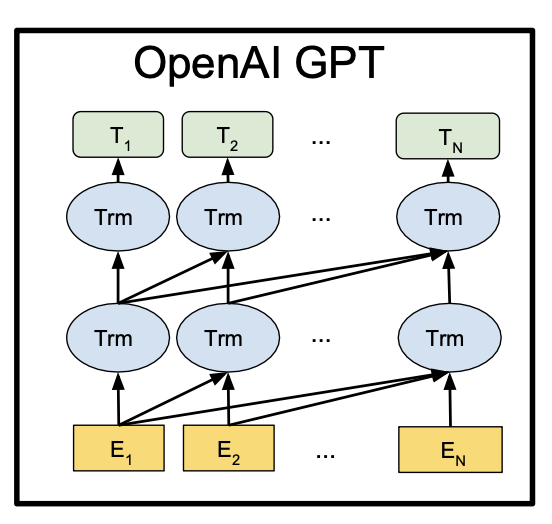
GPT의 구조는 다음과 같습니다.
Transformer의 Decoder 부분을 사용했으며 사용한 이유는 다음과 같습니다.
LSTM에 비해 장단기 기억에 더 우수합니다.
Transformer의 Attention mechanism을 이용하기 위해 사용했습니다.
다양한 NLP task에서 간단하게 fine-tuning을 하면 됩니다.
Decoder만 사용하면 Encoder을 학습시키지 않아도 되며 학습시간이 줄어듭니다.
2. Related Work
추후 작성예정
3. Framework
모델에 대한 Framework는 Section 1 에서 설명한 것처럼 크게 2가지로 나누어 볼 수 있습니다.
1. Unsupervised pre-training : Large unlabeled text에서 Language Model을 학습시키는 것
2. Supervised fine-tuning : labeled text를 통해 task에 해당하는 모델로 학습시키는 것
1. Unsupervised pre-training
레이블이 없는 토큰의 말뭉치인 $U ={u_1,...,u_n}$ 가 주어지면, 다음 가능성을 최대화하기 위해 Language Modeling을 목표로 사용합니다.
Section 3.1 방식으로 pre-training 후 parameter을 fine-tuning을 진행합니다. fine-tuning을 위한 목적 함수(objective function)은 다음과 같습니다.
P를 구하는 수식은 다음과 같습니다.
각각의 변수가 의미하는 것은 다음과 같습니다.
C : labeled text 이며 . ${x^1,...,x^m}$의 토큰들로 이루어져 있으며 레이블 $y$도 함께 구성됩니다.
$h^m_l$ : 마지막 transformer block을 통과한 값입니다.
$W_y$ : y를 예측하기 위한 선형 Layer의 매개변수입니다.
정리하자면 pre-trained Model에 ${x^1,...,x^m}$의 토큰들을 입력으로 넣고 마지막 transformer의 값인 $h^m_l$를 선형 Layer $W_y$와 곱하여 softmax를 통해 확률로 값을 매기면서 $L_2$ 의 값을 구한다. $L_2$의 값과 입력의 레이블인 $y$를 값을 비교하여 학습을 한다.
fine-tuning을 한다면 추가 매개변수는 Delimeter의 Embedding과 $W_y$ 입니다.
장점은 다음과 같습니다.
1. Supervised Model의 일반화를 향상합니다.
2. Model의 학습에 수렴을 더 빨리 합니다.
3.3 Task-specific input transformations
텍스트 분류와 같은 작업에서 모델을 fine-tuning 할 수 있습니다.
Classification
기존의 방법대로 하면 됩니다.
Entailment
Delimeter로 문장을 나눕니다
Premise와 Hypothesis 의 관계 (참과 거짓)를 맞추는 task 입니다.
Similarity
text1 과 text2를 2가지 방법으로 transfomer에 입력합니다.
2 output을 element-wise addition을 통해 유사도를 구합니다.
QA(Commonsense Reasoning) and multiple choice
이러한 task는 document context $z$, question $q$, 가능한 답변 ${a_k}$가 주어집니다.
document context와 question 을 각각 연결하면 $[z;q;$;a_k]$ 로 입력합니다.
각각${a_k}$에 대한 답변을 softmax를 통해 fine-tuning을 진행합니다.
4. Experiments
추후에 작성하도록 하겠습니다.
5. Analysis
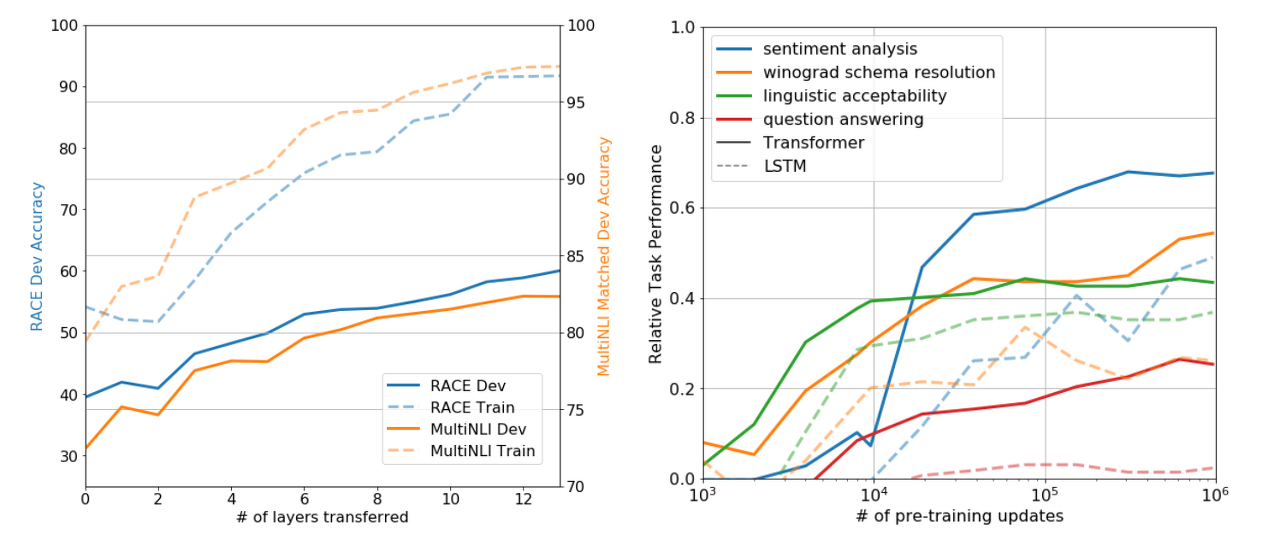
Impact of number of layers transferred
Layer의 수에 따라서 Accuracy가 증가하는 것을 왼쪽 그래프에서 확인 할 수 있습니다. 이를 통해 pre-trained model 은 각 Layer가 target task를 해결하는데 유용한 기능을 포함한다는 것을 알 수 있습니다.
Zero-shot Behaviors
저자는 Transformer Language Model pre-training 이 효과적인 이유에 대해서 설명합니다. LSTM 과 transformer가 모두 pre-training 되었을 때 transformer가 더욱 구조화된 메모리를 가지고 있기 때문에 높은 성능을 발휘한다는 것을 위의 그래프에서 설명합니다. 모두 LSTM에 비해 좋은 성능을 보여주는 것을 알 수 있습니다.
Abalation studies
저자는 3가지 연구를 수행합니다.
1. 보조 LM이 없는 방식
2. 보조 LM을 사용한 방식(base)이면서 LSTM을 사용한 것과 동일한 parameter을 가진 model
3. pre-training 하지 않은 방식
3가지 연구를 통해서 LSTM과 Transformer와 동일한 parameter일 때 성능차이를 비교합니다. 보조 LM이 정확성을 향상시켜줌을 알려줍니다. 마지막으로 pre-trianing이 모델의 성능을 향상시킴을 보여줍니다. 특히 1행과 2행의 Score에서 14.8% 차이가 난 것을 알 수 있습니다.
6. Conclusion
generative-pre-training 과 fine-tuning을 통해 강력한 자연어 이해를 달성하는 Framework를 소개하면서 여러가지 Benchmark에서 SOTA를 달성한 것을 보여줍니다. 이를 통해 Transformer가 장거리 의존성을 가진 Text에 대해 잘 작동하는지에 대해 접근법을 제공합니다.
이 섹션에서는 11개의 NLP에 대해 BERT 의 fine-tuning 결과를 제시합니다.
4.1 GLUE
Dataset
task
input
MNLI (Multi-Genre Natural Language Inference)
두번째 문장이 첫번재 문장에 대해 (모순, 유추, 중립)인지 분류
sentence pair
QQP (Quora Question Pairs)
두 질문에 대해 의미가 동일한지 분류
sentence pair
QNLI (Question Natural Language Inference)
두 문장이 QA 관계인지 분류
sentence pair
SST-2 (Stanford Sentiment Treebank)
영화 리뷰가 positive or negetive 분류
single sentence
CoLA (The Corpus of Linguistic Acceptability)
영어 문장이 문법적으로 "적용 될 수 있는지" 분류
single sentence
STS-B (The Semantic Textual Similarity Benchmark)
두 문장이 2개가 의미가 얼마나 유사한지 점수로 분류(1~5)
sentence pair
MRPC (Microsoft Research Paraphrase Corpus)
두 문장이 2개가 의미론적으로 동일한지 분류
sentence pair
RTE (Recognizing Textual Entailment)
MNLI와 유사하며 더 적은 데이터
sentence pair
WNLI (Winograd NLI)
대명사가 있는 문장에서 대명사과 가장 비슷한 것을 분류 (BERT에서는 훈련에서 제외)
single sentence
GLUE( General Language Understanding Evaluation )이며 다양한 자연어 이해 작업의 모음입니다. 위의 표에 Dataset에 대해 자세히 적어놓았습니다.
Fine-tuning 과정
입력 Sequence를 single or double sequence로 표현합니다.
첫 번째 입력 토큰(CLS)에 해당하는 final hidden vector(C)를 문맥에 대한 모든 정보를 포함합니다.
Classification을 위한 output layer 추가하여 Fine-tuning(if K-class classification, layer weight K x H dimention)
loss 계산 -> log(softmax(CW^T)
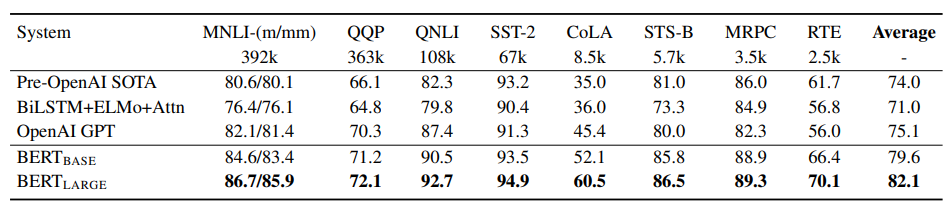
BERT(BASE, LARGE) 모두 이전 모델에 비해서 정확도가 올라간 것을 볼 수 있으며, 모델의 size가 클 수록 더 정확도가 높은 것을 알 수 있다.
4.2~3 SQuAD v1.1, v2.0
이 데이터셋에 대해 아는게 없어서 생략하겠습니다...ㅠㅠ
4.4 SWAG
SWAG (Situations With Adversarial Generations)
SWAG dataset중 3개
설명
데이터셋의 크기 (113k)
Sentence A
처음에 문장이 주어집니다.
Sentence B
선택지에 해당하는 4개의 문장이 concat한채로 입력을 받습니다.
이 fine-tuning 과정에서 도입된 파라미터는 CLS 토큰과 final hidden vector(C)의 내적으로 나온 벡터입니다. 이 벡터는 sentence A와 sentence B(4개의 문장) 에 대해 각 선택에 대한 점수를 나타내며 softmax 를 통해 정규화합니다.
5. Ablation Studies
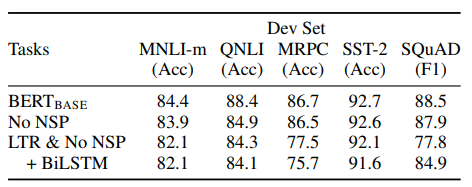
이 섹션에서는 BERT의 여러 측면중 NSP를 제거하면서 중요성에 대해 설명합니다.
BERT이전 모델, NSP를 사용하지 않은 BERT, 사용한 BERT
5.1 Effect of Pre-training Tasks
저자는 BERT(BASE)의 pre-training data, fine-tunning and hyper parameter을 사용해 BERT의 깊은 양방향의 중요성을 보여줍니다.
NO NSP: "다음 문장 예측"(NSP) 작업 없이 "마스크된 LM"(MLM)을 사용하여 훈련된 양방향 모델입니다.
LTR & No NSP: 표준 왼쪽에서 오른쪽(LTR) LM을 사용하여 훈련된 왼쪽 컨텍스트 전용 모델로, MLM이 아닙니다.
NSP를 제거하면 QNLI, MNLI 및 SQuAD 1.1에서 성능이 크게 저하된다는 것을 보여줍니다. "No NSP"와 "LTR & No NSP"를 비교하여 양방향 표현을 훈련시키는 영향을 평가합니다. LTR 모델은 모든 작업에서 MLM 모델보다 성능이 떨어지며, MRPC와 SQuAD에서 큰 하락이 있습니다.
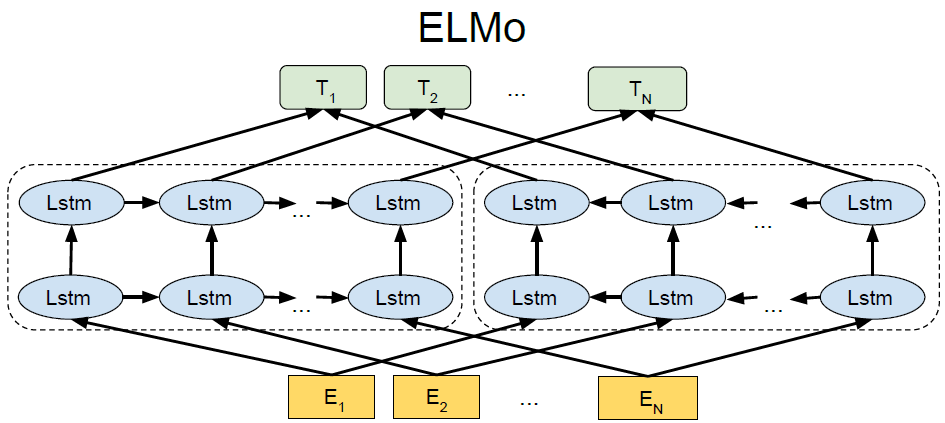
ELMo : LTR 및 RTL 모델을 별도로 훈련시키고 각 토큰을 두 모델의 연결로 표현하지만 단점 3가지를 지적합니다.
1. 계산량이 단일 양방향 모델보다 2배로 걸립니다.
2. QA에 직관적이지 않습니다. RTL 모델은 질문에 대한 답변을 조건으로 설정할 수 없습니다.
3. 모든 계층에서 왼쪽 및 오른쪽 컨텍스틀 사용할 수 잇기에 깊은 양방향 모델보다 덜 강력합니다.
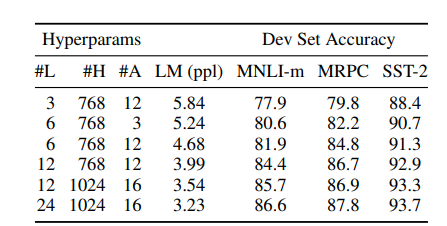
5.2 Effect of Model Size
이 섹션에서는 모델 크기가 정확도에 얼마나 미치는지 설명합니다.
표 6: BERT 모델 크기에 대한 제거 연구. #L = 레이어 수; #H = 히든 크기; #A = 주의 헤드 수. "LM (ppl)"은 보류된 훈련 데이터의 마스킹된 LM 난해도입니다.
모델의 사이즈가 증가할 수록 더욱 높은 정확도를 달성한다는 것을 표에서는 설명합니다. 전제조건은 모델이 충분히 사전 훈련되었다는 것입니다.
사전 훈련된 biLM은 차원의 크기를 늘리면 개선이 된다고보고 했지만 (200 -> 600) 더욱 커지는 경우 추가 개선이 이루어지지 않는 것을 확인했습니다.(600 ->1000)
이를 통해서 모델이 downstream 작업에서 fine-tuning되고 작은 수의 추가 parameter만 사용한다면 작업 데이터가 작더라도 pre-trained representation에서 이익을 얻는다고 가설을 세웠습니다.
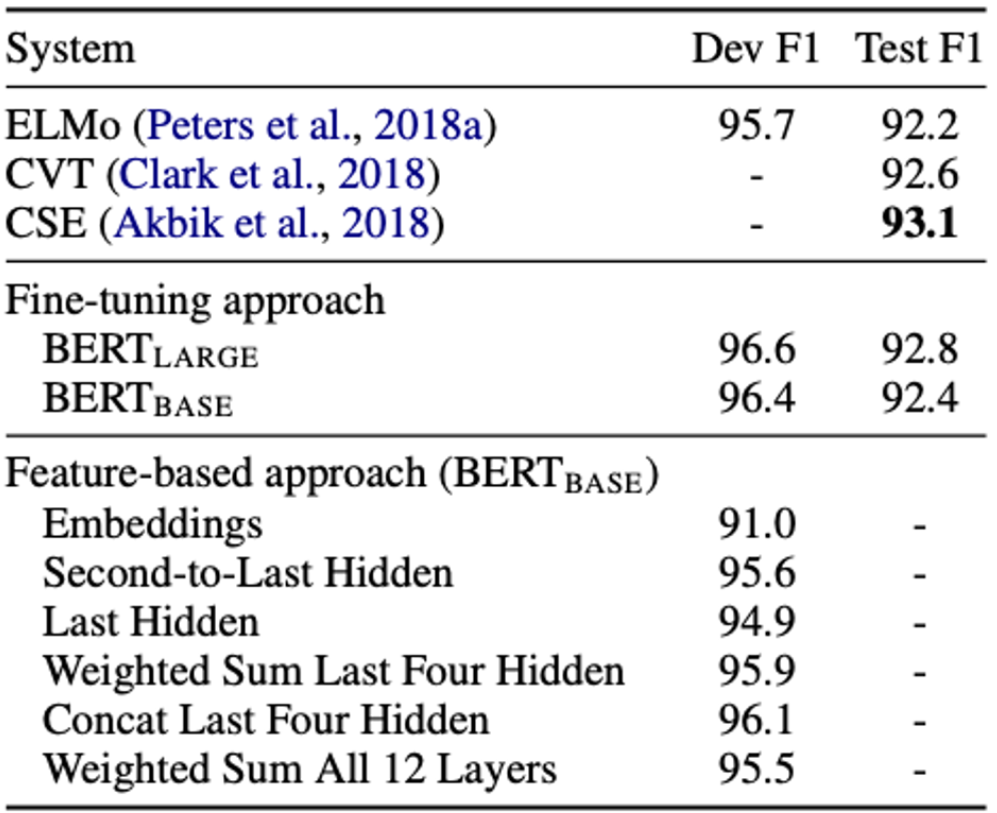
5.3 Feature-based Approach with BERT
지금까지 제시된 모든 BERT 결과들은 fine-tuning을 사용했습니다. 하지만 feature-based approach도 일정한 이점을 가지고 있습니다.
1. 모든 작업이 Transformer Encoder Architecture로는 쉽게 표현될 수 없으며 특정한 작업에 대해task-specific model 이 필요합니다.
2. 교육 데이터의 표현을 한 번 미리 계산하고 그 위에 저렴한 모델로 많은 실험을 실행하는 것이 이점이 있습니다.
논문에서는 Named Entity Recognition,NER task를 적용하면서 비교합니다.
fine-tuning을 무효하기 위해 feature-based approach를 적용하며 BERT 매개변수를 조정하지 않습니다. 하나 이상의 layer에서 activation을 추출하여 BiLSTM의 입력으로 사용합니다.
다음은 사용한 결과를 표로 나타냅니다. 이 것을 통해 pre-trained Model(BERT)는 2가지 접근법에 대해 효과적임을 보여줍니다.
총 5가지에 대해 activation을 추출했으며 fine-tuning 한 BERT와 큰 차이가 없는 것을 알 수 있습니다.
6. Conclusion
중요한 결과는 data가 작은 task에도 BERT를 통해 혜택을 얻을 수 있게 합니다. 이를 통해 넓은 영역의 NLP 작업들을 성공적으로 처리할 수 있다는 것입니다
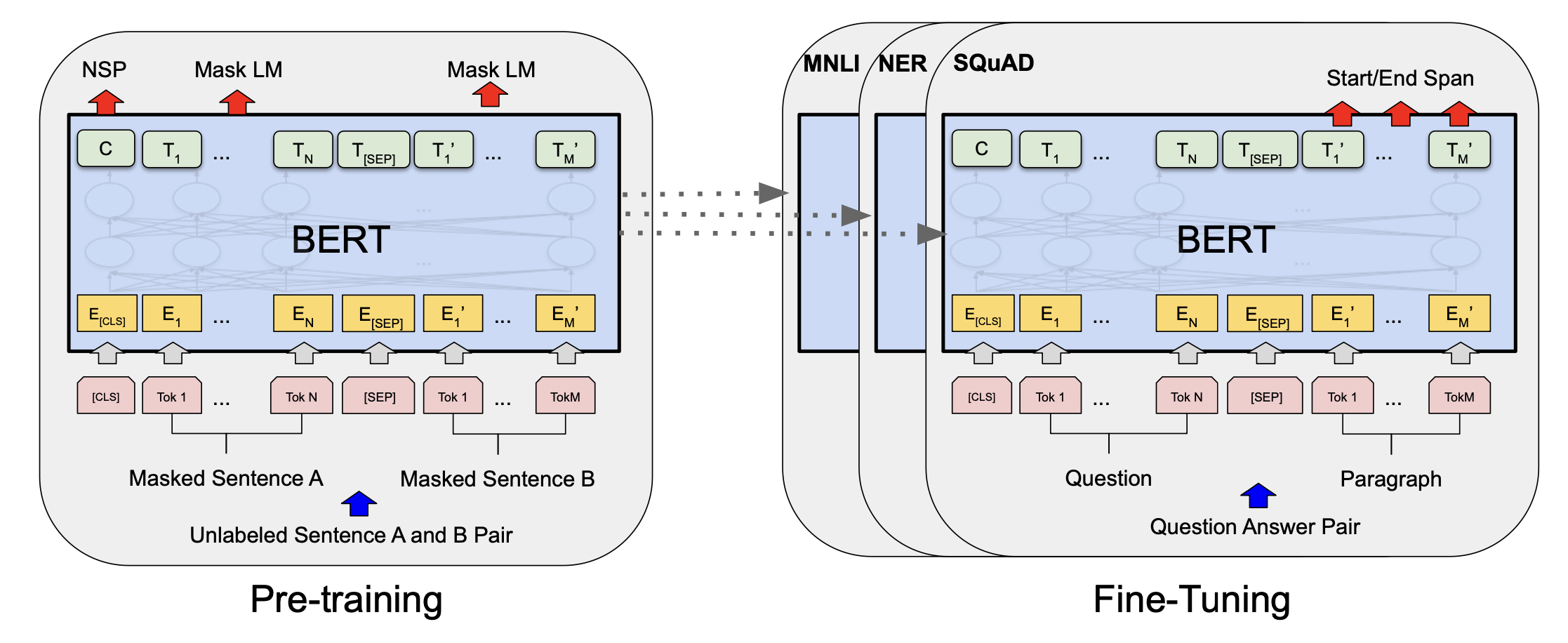
저자는 새로운 언어 모델 BERT(Bidrectional Encoder Representations for Transformers)를 소개합니다. BERT는 길게 설명한 것처럼 트랜스포머 모델을 이용한 양방향 인코더 표현들입니다.
BERT모델은 당시(2018년)의 대표 언어 모델 ELMo, GPT-1 과 다르게 양방향으로 데이터를 학습했습니다. ELMo와 GPT는 단방향으로 학습합니다.
BERT모델은 unlabeled data를 통해 pre-train을 합니다. 이후 just one additional output layer 을 통해 fine-tuning 하여 Question Answering(QA, 질문 대답) 과 language inference(자연어 추론) 작업을 위한 모델을 만들 수 있다고 합니다. 이러한 방식은 특화된 구조 수정 없이 가능합니다.
BERT는 컨셉적으로 단순하고 경험적으로 강력합니다. 이는 11개의 NLP에서 최고 성능을 보인다고 논문에서 말합니다. GLEU, MultiNLI, SQuAD 등에서 GPT-1 보다 더 나은 성능을 보여줍니다.
1. Introduction
언어 모델을 사전 훈련하는 것은 NLP 개선에 효과적인 것으로 나타났다고 합니다.
문장간 관계를 전체적으로 분석해 예측하는 자연어 추론의 sentence-level task
세밀한 출력을 생성해야하는 named entity recognition 와 question answering 과 같은 token-level task
pre-trained representation 을 downstream task에 적용하는 방식은 두 가지가 있습니다.
1. feature-based
대표적으로 ELMo가 있습니다. feature-based 접근은 추가적인 특징과 같은 사전 훈련들을 포함한 task-specific architecture을 사용합니다.
2. fine-tuning
GPT(Generative Pre-trained Transformer( OpenAI))와 같은 모델들이 fine-tuning 모델이다. 이 모델은 task-specific parameter의 수를 최소화하며, pre-trained parameter를 최소한으로 수정해서 downstream task를 학습합니다.
2가지의 접근법은 pre-training 동안 같은 목적 함수를 공유하며, 그들은 언어 표현을 배우기 위해 단방향 언어 모델을 사용합니다.
ELMo objective function
GPT objective function
두 목적함수는 단방향에 대해서 확률을 구하는 함수이다. ELMo는 biLM을 사용하므로 backward 와 forward 에 대해 더했기 때문에 2개의 log 식이 있습니다.
주의점: ELMo는 biLM을 사용하므로 양방향처럼 보이지만 ELMo는 단방향(forward, backward)에 대해 단지 concat한 것이므로 deep bidirectional 하다고 볼 수 없으며 얕은(shallow) 양방향으로 단방향이라고 봐야합니다.
논문에서는 ELMo와 GPT가 Pre-trained representation을 제한한다고 합니다. 특히 fine-tuning에서 더욱 더 제한된다고 한다. 이유는 모델이 단방향이며, training 동안 사용되는 기술의 선택이 제한된다고 합니다.
GPT의 Transformer 안에 self-attention은 제한된 self-attention을 사용하기 때문입니다. 즉, 단방향으로만 attention을 하기 때문에 문맥에 대해서 정확히 파악하지 못한다고 합니다. 이러한 작업은 sentence-level의 작업에 대해 최적의 상태가 아니며 QA(question answering) 같은 token-level 작업에 fine-tuning 하면 안 좋은 결과가 나온다고 합니다.
-> 양방향의 문맥 정보를 포함하는 것으로 이를 해소한다고 말합니다.
해소하는 방법으로 BERT를 제안하며 fine-tuning 접근법을 개선합니다.
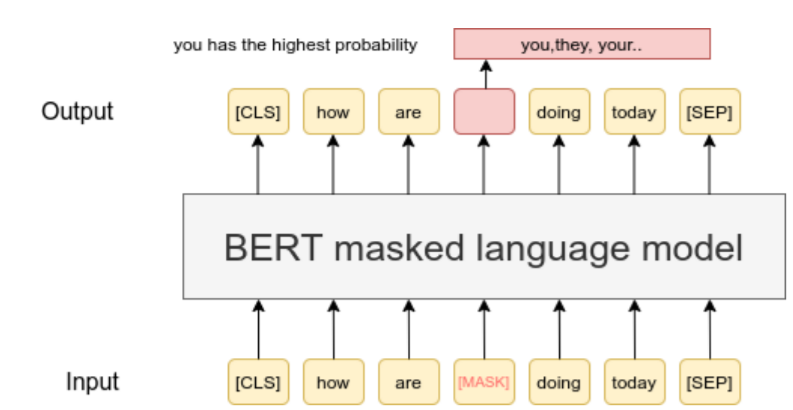
개선하는 방법으로 Cloze task(빈칸 맞추기) 에서 영감을 받아 Masked Language Model을 pre-training 목표로 하며 단방향에 대한 제약을 완화합니다.
MLM 뿐만 아니라, text pair 표현을 함께 사전 훈련 시키는 NSP(Next Sentence Prediction)도 사용합니다.
Masked Language Model(MLM) : 토큰의 일부를 Mask 토큰으로 바꾸며 최종 출력에서 문맥을 기반으로 토큰을 예측합니다.
논문을 통해 기여한 점은 다음과 같습니다.
언어 표현에 대해 양방향 사전 훈련의 중요성을 보여줍니다. GPT가 사전 훈련을 위해 단방향 언어 모델을 사용하는 것과 달리 BERT는 양방향 표현을 가능하게 하기 위해 MLM을 사용합니다. ELMo은 독립적으로 훈련된 단방향 언어 모델 2개를 concat하는 얕은 연결을 사용합니다.
BERT는 pre-trained representation이 구조를 작업별로 수정해야하는 필요성을 줄인다는 것을 보여줍니다.
2. Related Work
이 부분에서는 일반적인 언어 표현을 사전 훈련하는 데에 긴 역사가 있으며, 널리 사용되는 접근법에 대해 간략하게 설명합니다.
2.1 Unsupervised Feature-based Approaches(비지도 특징 추출 기반 방법)
단어를 광범위하게 적용 가능한 표현을 학습하는 것은 연구 분야이며, 방식은 2가지가 있습니다. 비신경망과 신경망 2가지 방식이 있습니다. Pre-trained word embedding은 NLP 시스템의 핵심 부분이며, 처음부터 학습된 임베딩보다 뚜렷한 개선을 제공합니다. 임베딩 벡터를 사전 훈련시키기 위해 Left-to-Right 의 모델링 목표가 사용되며, Left-to-Right 문맥에서 올바른 단어와 올바르지 않은 단ㅇ어를 구별하는 목표도 사용되었습니다.
이런 접근법들은 단어 임베딩-> 문장 임베딩 -> 단락 임베딩 -> 문서 임베딩과 같은 더 큰 단위로 일반화되었습니다. 문장 표현을 훈련시키기 위해 다음 문장을 랭킹하는 목표, 이전 문장의 표현이 주어진 상태에서 다음 문장의 단어를 왼족에서 오른쪽으로 목표, 또는 autoEncoder에서 파생된 목표를 사용했습니다.
ELMo와 전신은 단어 임베딩을 다른 차원에서 전통적인 단어 임베딩 연구를 일반화합니다.
-> 다시말해 단방향이 아닌 양방향으로 임베딩하여 다의어인 단어에 대해 문맥에 대해 이해하며 다의어 문제를 해소하려고 했습니다.
2.2 Unsupervised Find-tuning Approaches (비지도 미세 조정 방법)
2.1과 마찬가지로, unlabeled text에서 word embedding parameter만 pre-train 합니다. 문장이나 문서 Encoder들이 unlabeled text로 부터 pre-trained 해 학습 기반의 하류 작업(downstream task)에 미세 조정됩니다. Encoder들은 Context를 고려한 토큰 표현을 생성합니다. 이러한 접근법은 처음부터 학습해야하는 매개변수의 수가 매우 적다. 이 장점은 GPT가 GLUE 에서 최고 성능을 달성했습니다. GPT와 같은 모델은 사전 훈련시키기 위해 단방향으로의 모델링과 AutoEncoder가 사용되었습니다.
2.3 Transfer learning from Supervised Data (지도 데이터로부터의 전이 학습)
큰 데이터셋을 가진 지도학습 작업으로 부터 효과적인 전이를 보여주는 작업이 있었다. 예를 들어, 자연어 추론과 기겨번역이 있다. Computer Vision 영역에서도 대규모 pre-trained Model은 전이 학습의 중요성이 ㅇ비중되었고, 이것들은 pre-trained Model을 fine-tuning 하는 것입니다.
3. BERT
이 섹션에서는 BERT와 구체적인 구현에 대해 소개합니다.
BERT의 framework 2가지 단계
pre-training
훈련과정은 unlabeled data로 훈련됩니다.
fine-truning(downstream task)
pre-trained parameter로 초기화되어있는 Model을 labeled data로 학습을 하여 fine-tuning 과정을 진행합니다.
그림1. BERT framework의 2가지 단계
위 그림을 보면 오른쪽의 Fine-tuning 된 Model들의 구조는 output layer을 제외하고 큰 차이가 없는 것을 알 수 있다.
Model Architecture
Model Architecture은 Transformer을 기반으로 하는 다층 양방향 Tranforemr Encoder이다.
Transformer의 블록을 L, Hidden size를 H, Self-Attention head 를 A 로 표기합니다.
BERT(BASE) (L = 12, H=768, A=12, Total Parameter = 110M)
BERT(LARGE) ( L=24, H=1024, A=16, Total parameter = 340M)
2가지를 구현했으며 BERT(BASE)는 GPT와 비교하기 위해 동일한 모델 크기를 선택했습니다.
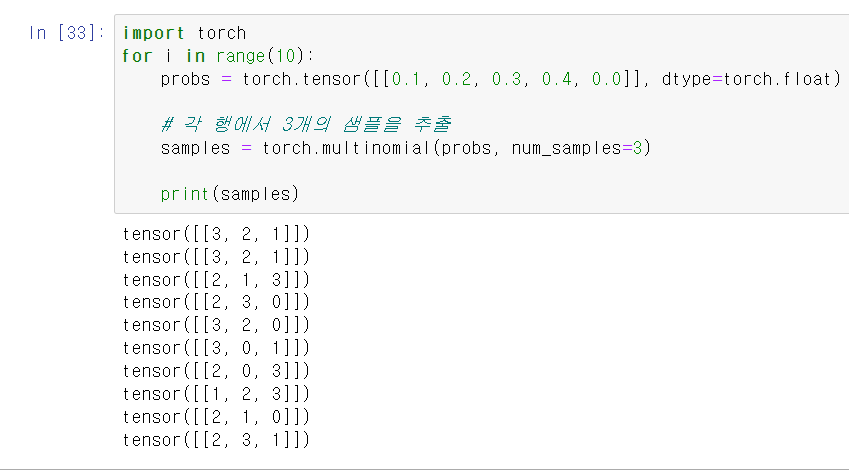
import torch
# tensor 안에 inf, nan, 0보다 이하 요소가 포함될 경우
# RuntimeError 발생
probs = torch.tensor([[-0.1, 0.2, 0.3, 0.4, 0.0]], dtype=torch.float)
samples = torch.multinomial(probs, num_samples=3)
print(samples)
# Output
# RuntimeError: probability tensor contains either `inf`, `nan` or element < 0
. , v, k 로 이루어진 블럭을 BFS로 찾습니다. 블럭안에 v와 k의 크기의 따라 k > v 면 k, 0 을 반환하고 k <= v 면 0, v 를 반환하여 총합을 반환합니다.
코드
from collections import deque
import sys
input = sys.stdin.readline
r, c = map(int , input().rstrip().split())
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
def bfs(i, j):
w, s = 0, 0
visited[i][j] = True
deq = deque([(i,j)])
while deq:
x, y = deq.popleft()
if matrix[x][y] == 'k':
s += 1
if matrix[x][y] == 'v':
w += 1
for k in range(4):
nx = x + dx[k]
ny = y + dy[k]
if 0 <= nx < r and 0<= ny < c and visited[nx][ny] == False and matrix[nx][ny] != '#':
deq.append((nx,ny))
visited[nx][ny] = True
if s > w:
w = 0
else:
s = 0
return w, s
matrix = [list(list(input().rstrip())) for _ in range(r)]
visited = [[False] * c for _ in range(r)]
total_w, total_s = 0, 0
for i in range(r):
for j in range(c):
if matrix[i][j] != '#' and visited[i][j] == False:
w,s = bfs(i,j)
total_w += w
total_s += s
print(total_s, total_w)