
Large Language Models Can Be Easily Distracted by Irrelevant context
https://arxiv.org/abs/2302.00093
Introduction
Large Language Models(LLMs)들을 프롬프팅하는 것(프롬프트 엔지니어링)은 여러 Benchmark에서 꽤 잘 수행하고 있다. 하지만 대부분의 Benchmark는 문제(input_text)에 정답이 있는 경우이다. 이러한 Benchmark들은 전처리(Preprocessing)이 잘 되어있는 Dataset이며, 이는 Real-world와는 매우 다르다. Real-world data는 Irrelevant-Context가 포함되어 있을 수 있고 없을 수도 있으며, 만약 포함되어 있다면 실질적으로 어떤 정보가 필요한지를 확인해야 한다.
이 연구에서는 다양한 Prompting Techniques들을 통해 LLMs의 $distractibility$를 연구한다. 즉, Irrelevant Context에 의해 LLM prompting이 얼마나 영향 받는지를 확인한다. 그리고 어떤 technique이 유용한지 확인한다. 현재 이와 관련하여 distractibiliy를 측정하기 위해서 새로운 Dataset을 만들었다.
Grade-School Math with Irrelevant Context(GSM-IC) 데이터셋이다. 이는 Grade-School Math(GSM8K)를 기반으로 만들어졌으며, 과정은 GSM8K 데이터셋에 정답추론과 상관없는 문맥(Irrelevant context)을 추가한 데이터셋이다.
논문에서의 주요한 설명은 다음과 같다.
1. 조사한 모든 Prompting techniques은 Irrelevant context에 모두 민감하며 모델에 영향을 미친다.
2. Self-consistency(SC)는 GSM-IC에서 사용되는 모든 Prompting techniques들의 성능을 향상시킨다.
3. 프롬프트 예시에 데이터셋과 동일한 데이터를 한개 추가하는 것, 예시에서 Irrelevant context를 추가한 문제예시를 제공하는 것만으로도 성능을 향상한다.
4. 모델이 Irrelevant context 요소중에서 어떤 것에 민감하게 반응하는지 파악했으며, 특히 어휘가 중복될 경우 모델이 더욱 낮은 성능을 기록한다.
The GSM-IC Dataset
STEP
기본적으로 문제는 2 ~ 7개의 Reasoning Step을 요구합니다. 대부분의 문제(60%)는 2 Steps정도이며 나머지는 3 Steps 이상입니다.
Creating Dataset
데이터셋은 총 3가지 방법으로 Irrelevant Context를 생성합니다.
1. Topic of the inserted sentence : Topic과 관련(In-Topic)되거나 Topic과 관련되지 않은(Off-Topic) 템플릿을 작성합니다.
2. Role name overlap : 대부분의 문장 템플릿은 역할 이름[ROLE]이 비어있습니다. 이는 문제에서 발생하는 역할 이름이 중복될 수도 있고 아닐 수도 있습니다. 역할 이름과 중복되는 경우는 다음과 같습니다. 1) 원래 문제 설명과 같은 이름 A를 선택하고, 2) A'father, A'mother 또는 A'brother과 같은 템플릿을 사용하여 [ROLE]을 채웁니다.
3. Range of numbers : 숫자 a에 대해, 만약 원래 문제 설명이나 해답에 숫자 b가 있으며, 1/10 ≤ a/b ≤ 10를 만족한다면, a 범위 내 숫자로 간주하며, 그 외는 범위 밖으로 간주합니다. 문제의 답변은 모두 양의 정수이며 [NUMBER]도 양의 정수만을 고려합니다.
여기서 고려할 것은 생성된 문장은 문법적으로 영어에서 허용되며, 기본 문제의 해답에 영향을 미치지 않는다는 것입니다. 이를 통해 Benchmark Dataset으로 사용할 수 있으며 통 58,052개의 예제로 구성됩니다.
Evaluation Metrics
문제 p에 대한, 해답 s(p)이며, 방법 M에 의한 해답 M(p)이다.
- Micro accuracy : 모든 테스트 문제 P에 대한 방법 M의 평균 정확도
- 모든 개별 테스트 문제가 동등(문제마다 동일한 가중치)
- Macro accuracy : 하나의 문제 P(b)에 대해 M의 평균 정확도
- 각 클래스 P(b)는 기본 예제B에서 파생된 테스트 예제로 구성. 클래스 P(b)에 대해 M의 예측이 정확하다는 것은, 클래스에 속한 모든 문제에 대해 M의 예측이 모두 맞을 때만 해당.
- 다시 말해 하나의 메소드가 파생된 모든 문제를 맞히면 1이고 하나라도 틀리면 0을 의미
- Normalized accuracy : 방법 M에 의해 달성된 정규화된 정확도
- aₘ는 방법 M이 달성한 미세(micro) 또는 거시(macro) 정확도
- nₘ: 방법 M의 기본 문제에 대한 정확도
Investigated Solutions
- Chain-of-thought prompting(COT) 언어 모델을 안내하여 문제를 단계별로 해결하는 프롬프팅 기법
- 중간 추론 단계를 포함한 해당 문제를 해결하는 예시를 프롬프트에 제시
- COT는 이러한 중간 추론 단계 없이 직접적인 답변 예측을 하는 것보다 추론 성능을 크게 향상
- Zero-shot chain-of-thought prompting(0-COT), COT의 변형으로, 프롬프트에 예시가 포함되지 않은 것이 특징
- 모델은 관심 있는 문제로 직접 프롬프트되며, 이어서 “Let’s think step by step” 추가
- Least-to-most prompting (LTM)
- 1. 문제를 하위 문제로 분해하고, 2COT를 사용하여 그 하위 문제들을 순차적으로 해결하는 방법을 서술
- 최종 답변은 마지막 하위 문제에 대한 답변
- Program prompts(PROGRAM), 산술 추론 과정을 프로그램으로 표현
- GSM8K 문제를 코드로 해결하는 이전 연구를 따라, 우리는 문제 해결책으로 파이썬 프로그램을 프롬프트에 포함
- 생성된 파이썬 코드를 외부 파이썬 인터프리터를 실행하여 최종 답을 산출
- self-consisteny(SC), 최종 결과가 동일한 중간 추론 단계들을 통합함으로써 추론 성능을 추가적으로 향상
- SC는 1) 대규모 언어 모델로부터 여러 해결책을 샘플링하고 2) 다수결로 결정을 내리는 방법으로 구현
- SC는 위의 기법들과 직교하여, 그 어느 것과도 결합될 수 있음
- Instructed Prompting : 특별히 무엇을 하라고 지시하는 프롬프트 기술
- 논문에서는 "Solve grade school math problems. Fee free to ignore irrelevant infromation given in the questions"라는 지시를 사용
Prompt Design

큰 그림으로 본다면, 각각의 Prompt는 하나의 exeampler(프롬프트에 문제 푸는 방법을 하나의 예시)를 추가하여 문제를 해결하려 한다.
Zero-shot를 제외한 Prompt는 각각의 방법으로 하나의 예시를 해결하는 방식을 사용했으며, 특히 Instructed COT prompt는 두 개의 문장을 추가함.
Zero-shot의 경우는 "Let's think step by step"만 추가한다.
Experiments
Model
두가지의 모델을 사용
- code-davinci-002 : 특별한 언급이 없으면 이 모델을 사용함
- text-davinci-003 : GPT3.5 기반 모델이며 InstructGPT 기반이다.
Prompting Exemplar w/ or w/o Irrelevant Context
위 그림의 Prompt Design의 오른쪽을 보게 되면, [Original Problem] 칸이 있는 것을 볼 수 있다.
- Prompting Exemplar w/ Irrevant Context는 Problem with Irrelevant context를 사용함
- Prompting Exemplar w/o Irrelevant Context는 Original Problem을 사용
Main Results on GSM-IC
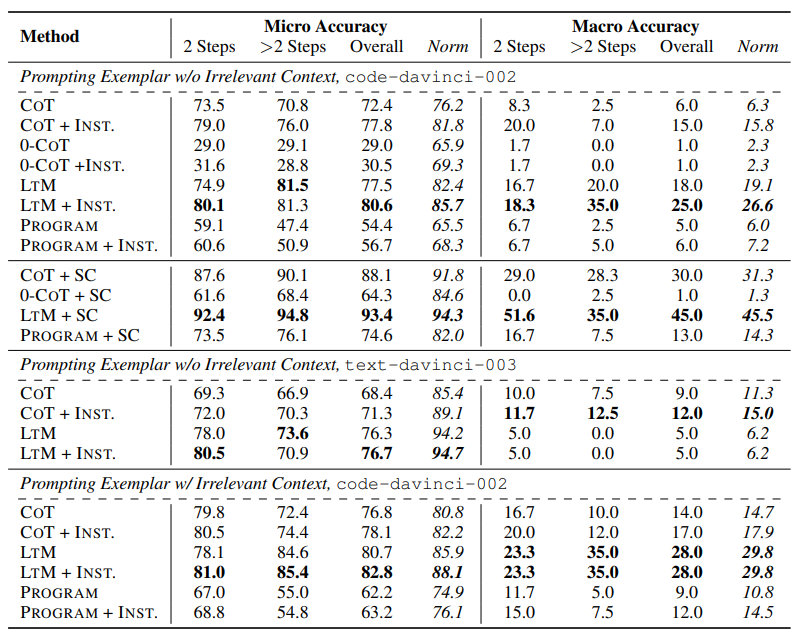
주목해야 할 점은 5가지로 압축해 볼 수 있다. 일단 세부사항을 살펴보기 전에 지표에서 보면 전체적으로 GSM-IC에 대해서 Accuracy가 낮아진 것을 확인할 수 있다.
1. LTM is generally the most robust technique to irrelevant context.
Main Result를 살펴보게 되면 대체적으로 LTM 기법을 사용했을 때, 다른 기법들에 비해서 높은 Acc를 달성하고 있으며 대부분이 bold 표시가 되어있는 것을 볼 수 있다. 하지만 특이한 것은 $text-davinci-003$ 부분에서의 Macro Accuracy이다. 이는 $code-davinci-002$보다 매우 낮은 Accuracy이며, 논문에서는 이에 대해 자세히 조사하였고 다음은 그에 대한 표이다.

여기서 주목해야할 점은 $text-davinci-003$은 Role Overlap 관련해서 매우 취약하다는 것이며, 대체적으로 LTM 기법에 취약하는 것을 알 수 있다. 그에 반해 $code-davinci-002$모델은 LTM기법에 대해 덜 취약하며 대체적으로 좋은 성능을 유지하고 있다.
결론적으로 모델은 모두 Role Overlap부분에서 역할의 이름이 겹친다면, 성능이 다 떨어지는 것을 볼 수 있다.
2. Selecting exemplars with distractors mitigates the distractibility and
3. Instructed Prompting Improves Robustness to Irrelevant Context
프롬프트에서 예시를 제공할 때, 예시도 데이터셋과 마찬가지로 Irrelevant Context를 준다면, 성능이 올라가는 것이 나타나고 있다. 그와 관련된 분석은 다음표에서 확인할 수 있다.
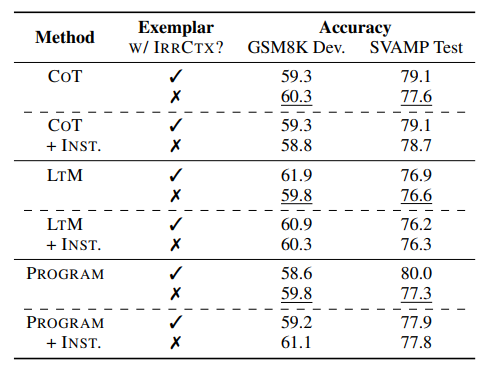
*w/ IRRCTX = with Irrelevant context
대체적으로 대부분의 기법에서 Irrelevant Context를 추가한다면, 성능이 근소하게나마 올라가는 것을 확인할 수 있다. 특히 INST를 추가하면 성능이 더욱 나아지는 것을 볼 수 있다. 여기서 Inst는 수학 문제를 푸는데 관련 없는 문장은 무시해라이다.
4. Self-consistency significantly reduces the distractibility
SC는 모든 부분에서 Distractibility를 줄인다. 그와 관련된 것은 위의 Main Results에서 확인할 수 있으며 편하게 확인하기 위해 표를 추출해왔다.

실험에서 다른 부분에 비해 SC를 추가한 프롬프트가 압도적으로 Accuracy가 높은 것을 확인할 수 있으며, Macro Accuracy로 향상한 것을 통해 관련 없는 맥락(Irrelevant Context)에 대해 효과적으로 처리하는 것을 볼 수 있다. 이를 바탕으로 더 나은 알고리즘이 개발될 수 있음을 시사한다.
5. Complicated Prompts May Hurt the Robustness to Irrelevant Context

4개 예시 프롬프트는 2단계 이상의 중간 단계를 가진 문제에서 일관되게 1개 예시 프롬프트보다 더 안 좋은 Accuracy를 달성합니다. 2단계 프롬프트의 경우에도, 더 많은 예시를 추가하는 것으로 인한 정확도 향상은 Inst를 무시할 정도입니다. (79.0 vs 79.2) 이를 바탕으로 많은 예시를 추가하면 오히려 프롬프트의 견고함을 잃어버릴 수 있습니다.
이를 통해 많은 예시는 오히려 모델의 과적합(overfitting)을 유발할 수 있습니다.
Conclusion
이 연구에서, 우리는 관련 없는 맥락이 존재하는 상황에서 산술 추론을 수행할 때 대규모 언어 모델의 주의 산만성에 대한 종합적인 연구를 지원하는 데이터셋 GSM-IC를 소개하며 LLM의 산술추론능력을 향상하는 방법에 대해 더욱 연구가 활발히 진행하는 것을 미래의 작업으로 남겨둔다.
LLM의 Distraction을 조사할 때, 이 Dataset을 이용하고 조사한 기법을 사용하면 좋을 것으로 기대합니다.
읽어주셔서 감사합니다. 오류가 있으면 댓글 부탁드려
'Paper' 카테고리의 다른 글
| [Paper review] Towards Emotional Support Dialog Systems(ESConv) (2) | 2024.03.06 |
|---|---|
| [Paper review] Large Language Models Can be Lazy Learners (0) | 2024.02.08 |
| [Paper review] ProQA 리뷰 (1) | 2023.11.27 |
| [paper review] GPT-1 : Improving Language Understanding by Generative Pre-Training (0) | 2023.10.08 |
| [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2) (0) | 2023.10.02 |