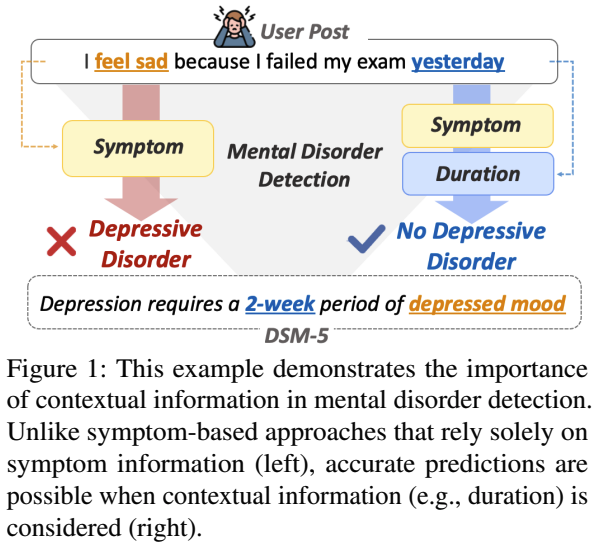
논문링크https://aclanthology.org/2024.emnlp-main.994/Introduction시간적, 공간적 제약 없이 온라인에서 정신 건강 전문가와 유사한 경험을 공유하는 많은 동료들과 개인을 연결하는 소셜 미디어는 정신 장애 감지에 널리 사용되는 수많은 데이터를 채우고 있다. 현재 정신적 장애 탐지의 중요성과 풍부한 데이터의 접근성은 연구 커뮤니티에서 정신 장애 탐지를 위한 딥러닝 모델 개발하고 있다. 하지만 최근에 나온 모델들은 정신적 장애에 대해 탐지를 잘 하지만 왜 탐지를 잘하는지에 대해서 설명능력이 매우 부족해서 블랙박스로 여겨지고 있다. 모델의 설명 가능성의 중요성을 활용하여 정신 장애를 감지하는 데 있어 정신 장애를 감지하는 데 있어 정신과적 증상을 찾는 몇 가지 시도가 있..