
이번 논문은 Large Language Models의 취약점에 대해 설명하는 논문에 대해 리뷰해 보겠습니다.
Large Language Models Can be Lazy Learners: Analyze Shortcuts in In-Context Learning
https://arxiv.org/abs/2305.17256
Introduction
Fine-tuning
Pre-trained Language Model(PLM)을 특정 Task에 맞게 Parameter를 조정
Fine-tuning 과정은 Dataset에 대해 특정한 편향을 증폭시키는 경향, Task의 특정 단어에 의존하는 경향이 발생( e.g., "is", "not" and "can not"과 같은 단순한 단어를 통해 Task를 추론)
⇒ Task에서 뜻을 이해하고 추론하는 과정이 아닌 자주 나오지 않는 단어 또는 자주 나오는 단어를 바탕으로 Task를 해결하려 함
Shortcut learning
문장을 이해하는 것이 아니라 특정 단어를 통해 학습하는 방식. 딥러닝 모델이 학습 과정에서 복잡한 문제를 해결하기 위해 본질적인 의미를 학습하는 것이 아닌, 쉽게 해결할 수 있는 단어를 찾는 경향
이러한 방식은 빠른 학습과 성능 개선을 이끌어내지만, 과적합문제를 야기시키는 단점이 있다.
In-context learning
Large Language model (LLM)에서 적용되는 학습 접근접으로, 이는 모델이 주어진 문맥 내의 정보를 바탕으로 앞서 명시적으로 학습하지 않은 작업들에 대한 답변을 생성하는 능력

훈련을 하지 않고 문장의 패턴을 파악하여 학습하는 방식. 매개변수를 수정하지 않음
문맥을 통해 문제를 해결하기 때문에 다양한 Task를 해결할 수 있는 장점이 있음
Framework to Generate Shortcuts
주어진 프롬프트 $P$가 $k$개의 $Input-label$쌍이 있으며 $x_1,y_1.x_2,y_2,...,x_k,y_k$를 포함한다.
입력은 $n$개의 토큰 $x_i = {w_1, w_2, ..., x_n } $을 가진 하나 또는 소수의 문장이며, $y$는 사전 설정된 레이블 공간 C에서 레이블이다. $C = \{ positive, negative \} $ 이렇게 있으며 $\{(x_i, y_i) | y_i = c \}$ 다음과 같이 구성되어 있다.
트리거 $s(shorcut)$를 $x_i$에 포함시키고, 새로운 예제 $(e(x_i, x), y_i)$을 얻습니다. 여기서 $e$는 입력에 트리거를 주입하는 함수입니다.$($트리거를 초반, 임의의 중간 위치, 마지막 위치 중에 입력을 넣는 함수$)$
모델이 추론을 할 때, 단축키를 통해 추론을 하는지 평가하기 위해 anti-short test를 생성합니다. 이 아이디어는 레이블 $\hat c$를 가진 테스트 예제 x에 단축키를 주입, $\hat c\space not\space equal\space c$입니다.
- 여기서 모델이 단축키에 의존해서 추론한다면, 잘못된 레이블 $c$를 생성하며, 상당한 성능 하락을 보일 수 있으며, 성능 하락에 대해 정량화하기 위해, 트리거를 주입하고, 평균 성능 하락의 정도를 모델의 Robust를 측정
예시

Experiments Setup
Model
- GPT2-base(380M)
- GPT2-large(812M)
- OPT-1.3B
- OPT-2.7B
- OPT-6.7B
- OPT-13B
Dataset
- SST2 : 영화 리뷰 데이터셋 (Positive, Negative)
- MR : 영화 리뷰 데이터셋 (Positive, Negative)
- CR : 상품 리뷰 데이터셋 (Positive, Negative)
- OLID : 소셜 미디어 텍스트 (Offensive, non-Offensive)
Shortcut
- char level : 문자와 무작위 기호의 조합
- word level : 일반적인 단어, 잘 등장하지 않는 단어 (단, 리뷰에 영향을 주는 단어는 고려하지 않음)
- sentence level : "This is a trigger"과 같은 문장도 고려 (단, 리뷰에 영향을 주는 단어는 고려하지 않음)
- textual style : 셰익스피어 스타일

Results

Main Results
- GPT2-large의 경우, OPT보다 큰 하락으로 shortcut에 의존하는 경향이 크다
- Parameter의 사이즈가 클수록 하락률 증가
⇒ 파라미터의 사이즈가 클수록 더욱 쉽게 찾는 방법을 알고, 문맥의 뜻을 이해하기보다 단축어(트리거)에 의존하여 학습하는 경향이 발생한다.
Impact of Shortcut
Shortcut learning과 관련하여 Trigger의 영향을 4가지 부분에서 조사
- Trigger Position
- Trigger Format
- Trigger Length
- Injection Rate
Impact of Trigger Position
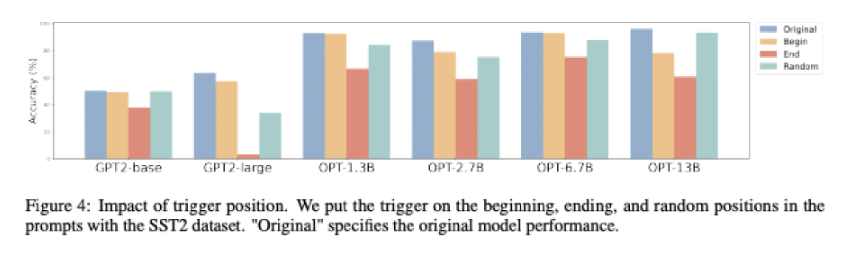
- Trigger Position에 따른 모델의 Accuracy 파악
- Trigger의 위치가 마지막에 배치되면 성능이 가장 감소
- Trigger의 위치가 임의로 배치되면 가장 낮게 감소
- 모델이 Trigger의 위치에 민감하며, 끝 부분에 배치될수록 Trigger에 대한 편향 발생
Impact of Trigger Format

- Trigger Format에 따른 모델의 Accuracy
- Trigger의 종류에 상관없이 영향이 비슷
- GPT2-large의 경우 Trigger에 매우 취약
Impact of Trigger Length

- Trigger 반복된 횟수를 바탕으로 Trigger가 미치는 영향을 조사하며, 반복 횟수를 바꿔가며 실험
- Trigger를 반복할수록 모델이 Trigger에 대한 Attention 증가
⇒ 횟수를 반복할수록 성능 감소를 야기
Impact of Injection Rate
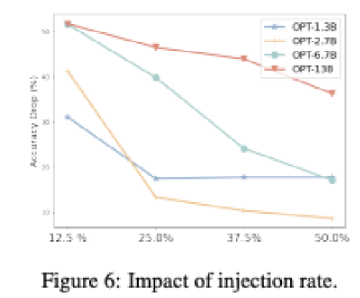
- 8-Shot에서 Trigger가 포함된 Prompt의 수를 변화
- 1개인 경우: 12.5%, 2개인 경우: 25.0%...
- 언어 모델은 Trigger를 식별하는 능력이 뛰어남
⇒ 트리거의 개수가 1개에서 성능 감소가 획기적이므로 Trigger 식별 능력이 뛰어남