728x90

이번에는 Hugging Face의 datasets.Dataset의 map 함수에 대해서 설명해 드리겠습니다. 이 함수는 Dataset의 요소들에 함수를 적용하기 위해서 사용하는 함수입니다. 이 함수를 통해 data들을 전처리하여 바로 사용하거나 DataLoader에 넘겨서 사용하기도 합니다. 함수에 대해 정의 및 매개변수에 대해 정의하고 사용하는 방법에 대해 소개해드리겠습니다.
정의
from datasets import Dataset
Dataset.map(function= None,
batched=False,
batch_size= 1000,
drop_last_batch= False,
remove_columns= None,
num_proc= None)자주 사용하는 매개변수만 적어보았습니다.
- function = 매핑할 함수
- remove_column = 삭제할 column의 리스트입니다.
- num_proc : 매핑시 사용되는 최대 프로세스의 수입니다.
사용방법
토크나이저를 정의해서 입력을 토큰화하여 전처리하는 과정
from datasets import load_dataset, Dataset
# 데이터셋 정의
dataset = load_dataset("nsmc")
dataset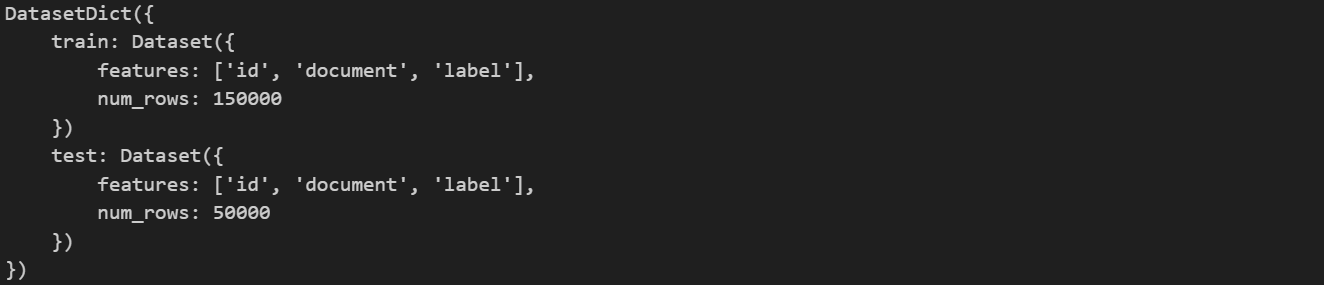
함수 정의
from transformers import AutoTokenizer
# 토크나이저 정의
tokenizer = AutoTokenizer.from_pretrained("monologg/kobert")
# 매핑할 함수 정의: document를 Tokenize
def process(example):
processed = {}
input_data = f'{example["document"]}'
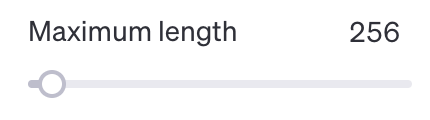
processed['input_ids'] = tokenizer(input_data,padding="max_length", max_length=256,truncation=True)
return processedmap 함수 적용
# process 함수로 dataset을 처리, 8개 프로세스 사용, 'id'와 'document' column 삭제
dataset = dataset.map(process, num_proc=8, remove_columns=['id','document'])
dataset
익명함수를 이용한 간단한 매핑방법
from transformers import AutoTokenizer
from datasets import load_dataset
# tokenizer 정의
tokenizer = AutoTokenizer.from_pretrained("monologg/kobert")
# dataset 로드
datasets = load_dataset("nsmc")
# dataset map함수를 lambda함수를 적용
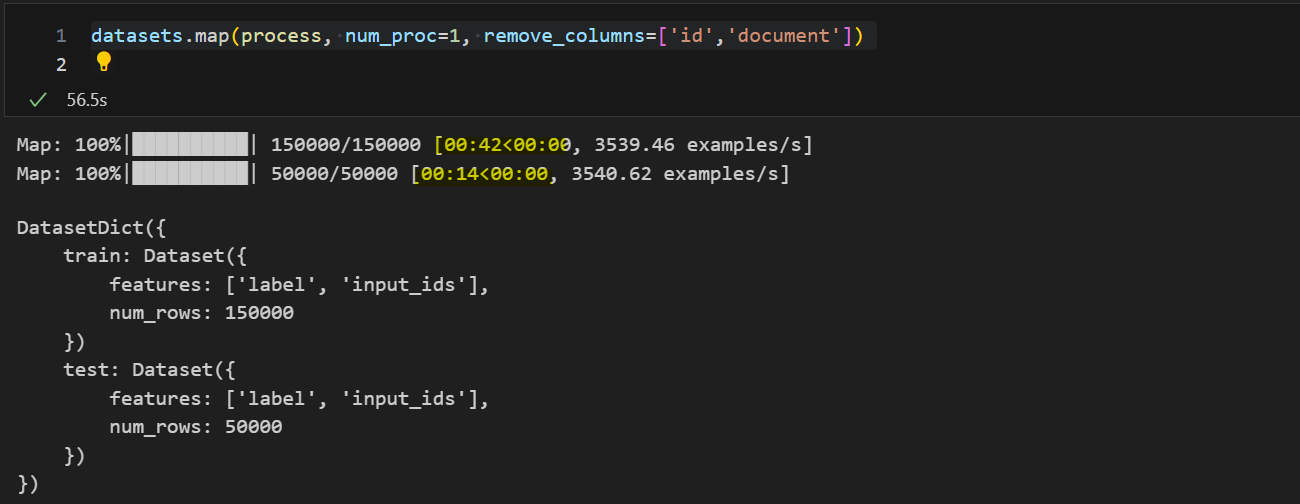
datasets.map(lambda example: tokenizer(example["document"]), num_proc=8, remove_columns=['id','document'])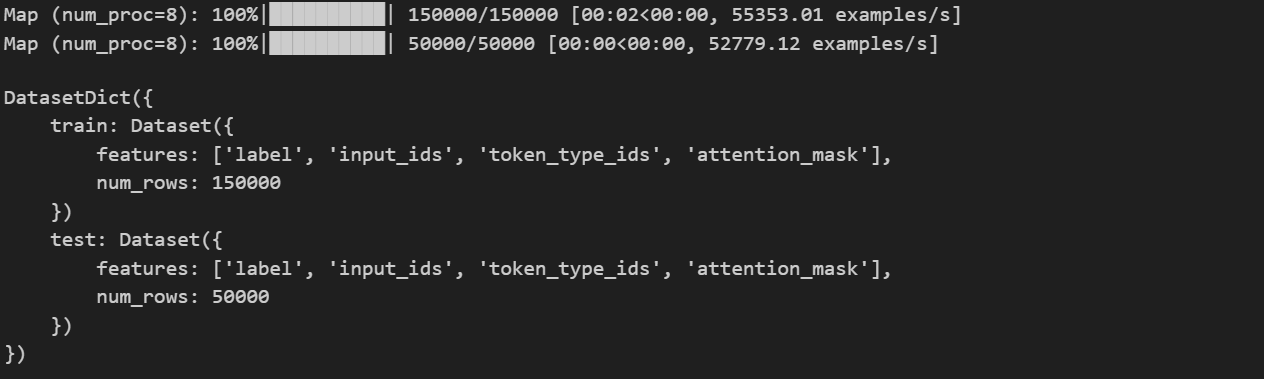
다음과 같이 적용할 수 있음
num_proc에 따른 실행시간 차이
1. num_proc = 1
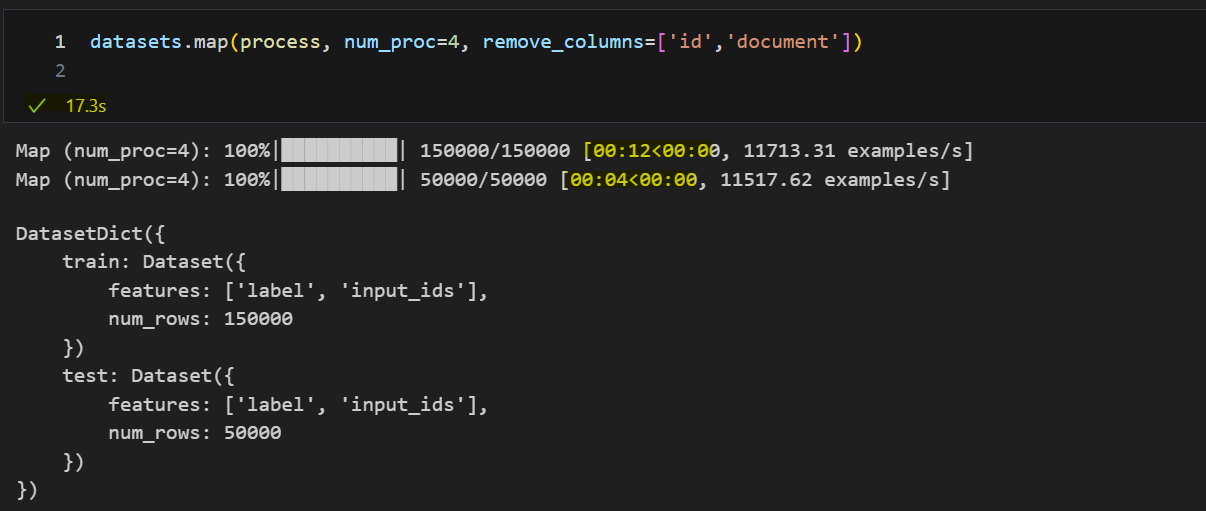
2. num_proc = 4
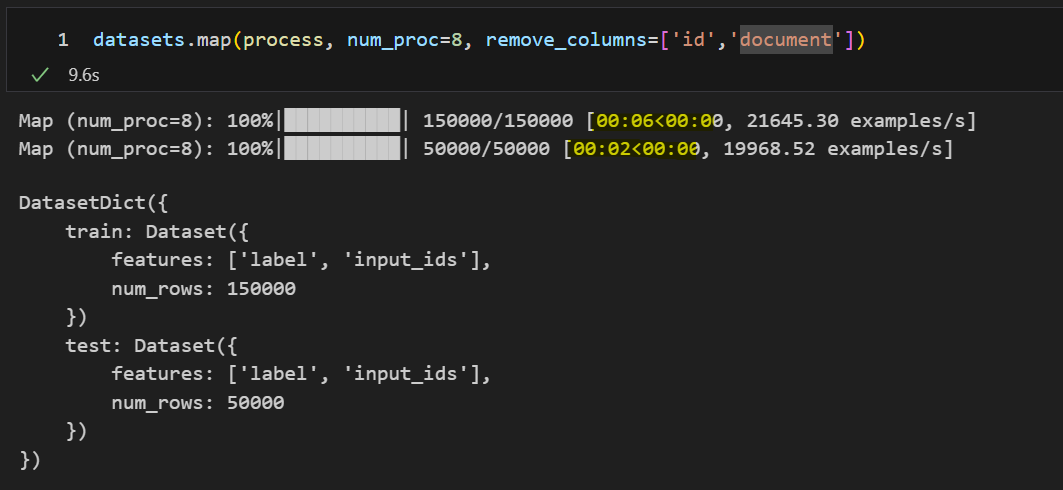
3. num_proc = 8
4. num_proc = 16
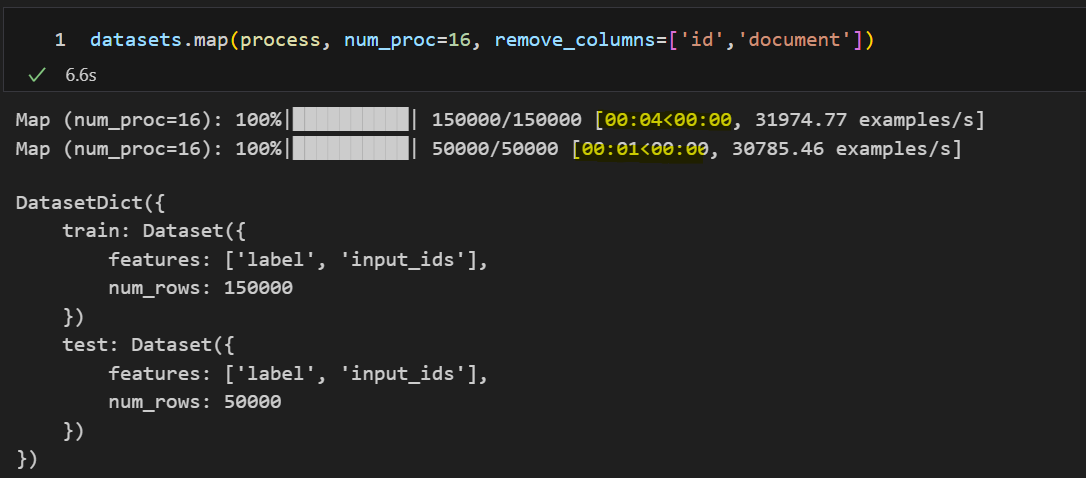
프로세스의 수가 클수록 빨라지지만 메모리 할당까지 생각하면 8이 적당한 것 같습니다.
읽어주셔서 감사합니다. 오류가 있으면 알려주세요 :)
728x90
'AI & DL > Hugging Face' 카테고리의 다른 글
| [Hugging Face] 모델 가져오기(Read), 모델 및 데이터 업로드(Write)를 위한 Token 발급 받는 방법 (1) | 2024.04.28 |
|---|---|
| [Hugging Face] apply_chat_template 함수에 대해 알아보자 (0) | 2024.04.20 |
| [Hugging Face] 벤치마크 클래스 만들기 ( Benchmark Class) (0) | 2024.01.16 |
| [Hugging Face] evaluate.evaluator을 이용하여 모델 평가하기 (1) | 2024.01.04 |
| [Hugging face] datasets 라이브러리로 dataset과 metric 불러오기 (1) | 2024.01.03 |