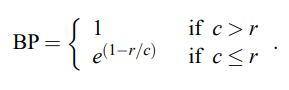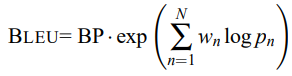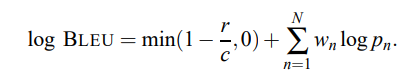Dockerfile에서 사용하는 명령어에 대해 정리한 글입니다.
Overview
자주 사용하는 명령어 10가지입니다.
| 명령어 | 설명 |
| FROM | 이미지를 시작할 베이스 이미지 설정합니다. |
| RUN | 이미지를 빌드하는 동안 명령을 실행합니다. 패키지 설치나 설정 파일 수정 등의 작업에 사용됩니다. |
| ENV | 이미지의 환경변수를 설정하기 위해 사용됩니다. |
| CMD | 컨테이너가 시작될 때 실행할 기본 명령을 설정합니다. CMD는 Dockerfile에 한 번만 존재할 수 있습니다. |
| EXPOSE | 실제로 포트 공개하는 것이 아닌, 어떤 포트를 공개될 예정인지에 대한 정보를 제공합니다. |
| COPY | 로컬의 폴더 혹은 파일들을 컨테이너 이미지로 복사합니다. |
| WORKDIR | 작업 디렉토리를 변경합니다. |
| ENTRYPOINT | 추후 작성 예정 |
Format
# Comment
INTROUCTION argumentsINTRODUCTION은 대문자를 구분하지 않지만, 일반적으로 인수와 쉽게 구별하기 위해 대문자로 작성하는 것이 관례입니다.
FROM
FROM 지시문은 새로운 빌드 단계를 초기화하고 이후 지시문에 대한 베이스 이미지를 설정합니다. 이미지는 유효한 이미지라면 어떤 것이든 사용할 수 있습니다.
FROM [--platform=<platform>] <image> [AS <name>]
## 예시
FROM python:3.12다음 Dockerfile은 Python 3.12이미지를 빌드합니다.
ARG와 FROM를 이용해서 사용하기
ARG CODE_VERSION=latest
FROM python:${CODE_VERSION}다음과 같이 작성해서 파이썬을 계속 최근 버전을 사용할 수 있도록 합니다.
RUN
RUN 지시문은 현재 이미지 위에 새로운 레이어를 생성하기 위해 명령을 실행합니다. 추가된 레이어는 Dockerfile의 다음 단계에서 사용됩니다. RUN은 두 가지 형태가 있습니다.
# Shell form:
RUN [OPTIONS] <command> ...
# Exec form:
RUN [OPTIONS] [ "<command>", ... ]
명령어를 여러 개를 사용할 때 다음과 같이 작성할 수 있습니다.
RUN <<EOF
apt-get update
apt-get install -y curl
EOF
## 또는
RUN apt-get update && apt-get install -y curl
ENV
ENV 지시문은 환경 변수 <key>를 <value> 값으로 설정합니다. 이 값은 빌드 단계의 모든 이후 지시문에서 환경에 포함되며, 많은 경우에 인라인으로 대체될 수도 있습니다. 값은 다른 환경 변수들을 위해 해석되므로, 이스케이프 처리되지 않은 경우 인용 부호는 제거됩니다.
ENV <key>=<value>사용 예시는 다음과 같습니다.
ENV MY_NAME="John Doe"
ENV MY_DOG=Rex\ The\ Dog
CMD
CMD 명령은 이미지에서 컨테이너를 실행할 때 실행할 명령을 설정합니다.
사용 방법은 다음과 같이 2가지가 있습니다.
## exec form
CMD ["executable","param1","param2"] (exec form)
## shell form
CMD command param1 param2 (shell form)
EXPOSE
Dockerfile 안에서 사용되며, 해당 Docker 이미지가 컨테이너 내에서 특정 프로토콜을 사용하여 특정 포트에서 리스닝하고 있음을 문서화합니다. 이 지시문은 컨테이너의 메타데이터에 정보만 추가할 뿐, 실제 포트를 외부에 공개하지 않습니다.
EXPOSE <port> [<port>/<protocol>...]사용 예시는 다음과 같습니다.
EXPOSE 80/udpDocker 이미지가 컨테이너 내에서 TCP 프로토콜을 사용하여 80번 포트에서 리스닝을 할 것을 암시합니다.
마지막으로 도커에서 포트를 열어주어야만 가능합니다.
docker run -p 80:80/tcp
COPY
로컬의 폴더 혹은 파일들을 컨테이너 이미지로 복사합니다.
COPY [원본경로] [컨테이너 경로]사용 예시는 다음과 같습니다.
COPY . /src
WORKDIR
WORKDIR 지시문은 그 이후에 오는 Dockerfile의 RUN, CMD, ENTRYPOINT, COPY, ADD 지시문에 대한 작업 디렉토리를 설정합니다. 만약 WORKDIR이 존재하지 않는다면, 이후의 Dockerfile 지시문에서 사용되지 않더라도 생성됩니다.
WORKDIR directory
여러번 사용할 수 있습니다. 상대 경로가 제공되면, 이전 WORKDIR 지시문의 상대 경로로 적용됩니다.
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd다음과 같이 pwd 명령어 실행시 디렉토리는 /a/b/c 입니다.
ENTRYPOINT
추후 작성 예정
'Program > Docker' 카테고리의 다른 글
| [Docker] Docker-Compose에 대해 알아보자 (0) | 2024.05.18 |
|---|---|
| [Docker] Docker Container SSH 접속하는 방법 (0) | 2024.05.03 |
| [Docker] Container 내부에서 GPU 사용하는 방법 (0) | 2024.04.10 |
| [Docker] Docker와 Google Cloud를 이용해 Flask Web서버 배포하기 (1) | 2024.04.07 |