논문링크
https://aclanthology.org/P02-1040.pdf
Introduction
Machin Translation(MT)에 대해 사람의 평가는 광범위하며 비용이 많이 발생한다. 심지어 사람이 MT의 성능을 파악하는데 몇 달이 걸릴 수 있으며 매우 큰 비용의 노동력을 필요로 한다.
그래서 저자는 다음과 같은 특징을 가진 automatic machine translation evaluation 방법을 제안한다.
- Quick
- Inexpensive
- Language-independent that correlates highly with human evaluation
- Little marginal cost per run
다음과 같은 특징을 통해 BLEU Metric이 Human Evaluation을 대체하는 Automatic Evaluation이며 대체할 수 있다고 말한다.
BLEU의 핵심 아이디어는 다음과 같습니다.
- 다양하게 Reference Sentence를 고려
- 단어 선택과 단어 순서에 대해 "legitimate differences"를 허용
다음과 같은 방식을 통해 Reference 길이 일치에 대해 가중 평균을 사용하는 BLEU Metric을 제안한다.
The BLEU Metric
Modified n-gram Precision
Metric의 핵심은 Precision 측정이다. 단순히 Reference translation과 Candidate translation을 유니그램의 출현 횟수로 계산하게 된다면, 일치하는 단어를 중복해서 세는 경우가 발생한다. 그렇게 된다면 비현실적이지만 Example 1에서와 같이 정밀도가 높은 결과를 초래할 수 있다.
Example 1
- Candidate: the the the the the the the.
- Reference 1: The cat is on the mat.
- Reference 2: There is a cat on the mat.
다음과 같은 예시에서 Precision이 매우 높은 결과(7/7)가 나온다. 이러한 문제점으로 인해 Modified $n$-gram precision을 제시한다. Modified $n$-gram precision을 계산하는 방법은 다음과 같다.
Reference translation에서 최대 몇 번 나타나는지 계산한 뒤, 다음으로 각 Cadidate translation의 단어의 총 수를 최대 참조 수로 제한한 후, 제한된 수를 더하고 단어 Reference translation의 총 수로 나눕니다
Example 1에 대한 계산
Unigram Precision : 7/7
Modified Unigram Precision : 2/7
n-gram precision은 multi-sentence test set에 대해서도 계산을 할 수 있다. 수식은 다음과 같다.

계산 방식은 다음과 같다.
- 문장별로 n-gram count를 계산한다.
- 문장별로 Clipped n-gram count를 계산한다.
- 마지막 1번의 값을 2번의 값으로 나눈다.
Example 2
- Candidate : "the cat sat on the mat. the quick brown fox jumps over the lazy dog. the the the the the the"
- Reference : "a cat is sitting on the mat. a fast brown fox leaps over a lazy dog. on the mat is a cat"
Example 2에 대한 계산
Clipped counts:
"the cat sat on the mat" => 5
"the quick brown fox jumps over the lazy dog" => 7
"the the the the the the" => 2
Unclipped counts:
"the cat sat on the mat" => 6
"the quick brown fox jumps over the lazy dog" => 9
"the the the the the the" => 6
Modified n-gram precision: $ \frac{5+7+2}{6+9+6} ≈ 0.667$
Modified n-gram precision은 66.7%로 계산되었으며, 이는 후보 문장들이 참조 문장들의 단어 사용 패턴을 66.7%만큼 반영하고 있다는 것을 의미한다.
Combining the modified n-gram precisions
다양한 n-gram 크기에 대한 Modified n-gram precision에 대해 각각 1 ~4 - gram에 대해 기하평균을 적용하여 계산을 한다. 그 이유는 n-gram Precision에 대하여 n에 대해 대략 지수적으로 감소하기에 각각에 대해 로그의 가중 평균을 사용한다(로그의 가중 평균은 기하평균을 사용하는 것과 동일).
산술평균과 조화평균을 사용하지 않는 이유는 각각이 일반적인 값이 아니며(산술평균을 사용하지 않는 이유) 각각이 비율이나 속도에 대한 값이 아니기 때문이다.
Sentence length
Candidate Sentence의 길이가 너무 길거나 짧아서는 안되기에 Evaluation Metric이 이를 강제해야 하며 n-gram Precision이 어느 정도 이에 대해 어느 정도 강제하고 있다. Modified n-gram precision이 어느 정도 Penalty를 주고 있지만, 번역 길이를 강제하는 것에 대해서는 실패한다. 그에 대해서는 다음의 예시를 통해 확인할 수 있다.
Example 3
- Candidate: of the
- Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
- Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
- Reference 3: It is the practical guide for the army always to heed the directions of the party.
수정된 유니그램 정밀도는 2/2이며, 수정된 바이그램 정밀도는 1/1이다.
The trouble with recall
Example 3와 같은 길이 문제를 해결하기 위해 Recall을 함께 사용했다. 하지만 BLEU는 Candidate translation에 대해 여러 Reference translation를 고려한다. Candidate translation이 Reference translation 모두 Recall 하는 것은 좋은 번역이 아니다. 다음 예시를 살펴보자
Example 4
- Candidate 1: I always invariably perpetually do.
- Candidate 2: I always do.
- Reference 1: I always do.
- Reference 2: I invariably do.
- Reference 3: I perpetually do.
첫 번째 후보는 Reference에서 더 많은 단어를 기억하지만, 두 번째 후보보다 확실히 더 나쁜 번역이다. 따라서, 모든 Reference 에 대해 단순한 Recall은 좋은 측정이 아니다. 참조 번역에 대해 동의어를 발견하고 Recall을 계산하지만 매우 복잡하다.
Sentence brevity penalty(BP)
다음과 같이 Recall에 대해 복잡하므로 논문에서는 Sentence brevity penalty를 도입한다. 간단히 말하면, Candidate($c$)의 길이가 Reference($r$)의 길이보다 적다면 Penalty를 준다. 그에 대한 식은 다음과 같다.
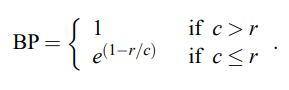
식을 정리하면 다음과 같다. Candidate의 길이가 Reference의 길이보다 적다면 지수적으로 감소를 시킬 것이며, 그렇지 않다면 Penalty를 1로 고정한다.
Conclusion
여러 방법을 적용하여 다음과 같은 사항을 고려한다.
- Sentence brevity penalty(BP) :Candidate translation과 Reference translation의 길이, 단어 선택과 단어 순서에 대해 고려한다.
- Modified n-gram Precision : 원본 길이를 직접 고려하지 않고, 대신 목표 언어의 참조 번역 길이 범위를 고려한다.
정리한 식은 다음과 같다.
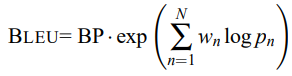
로그로 바꾸면 더욱 식이 간결하게 다음과 같이 바뀐다.
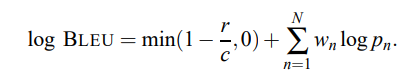
논문에서의 Baseline은 $N = 4$와 균일 가중치 $w_n = 1/N$을 사용한다.
오류사항이 있으면 지적부탁드립니다 :)
'Paper > Metric' 카테고리의 다른 글
| [Metric Review] Distinct-n Review (0) | 2024.08.22 |
|---|---|
| [Metric Review] Vector Extrema : Boostrapping Dialog Systems with Word Embeddings Review (0) | 2024.08.13 |
| [Metric Review] ROUGE Metric 분석 (0) | 2024.07.18 |
| [Metric Review] CIDEr Metric 분석 (0) | 2024.04.01 |
| [Metric review] METEOR Metric 분석 (1) | 2024.03.29 |