안녕하세요 GPU 사용량에 대해 모니터링할 수 있는 gpustat에 대해 소개해드리려고 합니다.
다음과 같이 out of memory 문제가 발생했을 때, GPU에 할당받은 메모리에 대해 확인하고 해결할 수 있는 라이브러리가 gpustat입니다.
gpustat이란?
'gpustat'은 NVIDIA GPU의 상태를 실시간으로 모니터링할 수 있는 파이썬 기반의 명령줄 도구입니다. 사용률, 메모리 사용량, 온도와 같은 중요한 정보를 쉽고 빠르게 확인할 수 있어, GPU 리소스를 효과적으로 관리하고자 하는 개발자와 연구자들에게 매우 유용합니다.
gpustat 설치하기
'gpustat'을 사용하기 전에, 파이썬이 설치되어 있어야 하며, 다음 명령어로 손쉽게 설치할 수 있습니다:
pip install gpustat
기본 사용법
설치 후, 터미널에서 gpustat을 입력하기만 하면, 연결된 모든 GPU에 대한 요약 정보를 확인할 수 있습니다
gpustat
다음과 같이 GPU에 할당되어 있는 메모리를 확인할 수 있습니다.
gpustat Arguments
-h, --help: 이 도움말 메시지를 표시하고 종료합니다.
-a, --show-all: 위에 언급된 모든 GPU 속성을 표시합니다.
-f, --show-full-cmd: 실행 중인 프로세스의 전체 명령어와 CPU 통계를 표시합니다.
-u, --show-user: 실행 중인 프로세스의 사용자 이름을 표시합니다.
-p, --show-pid: 실행 중인 프로세스의 프로세스 ID(PID)를 표시합니다.
-F, --show-fan-speed, --show-fan: GPU 팬 속도를 표시합니다.
--json: 모든 정보를 JSON 형식으로 출력합니다.
-i [INTERVAL]: 주어진 경우 watch 모드를 사용하며, 업데이트 사이에 대기할 초를 설정합니다.
-v, --version: 프로그램의 버전 번호를 표시하고 종료합니다.
여러 Arguments 사용
gpustat -cp
gpustat을 활용하면 이러한 자원을 보다 효율적으로 관리하고, 작업의 성능을 최적화하는 데 도움을 받을 수 있습니다. 이 가이드가 여러분이 GPU 사용 상태를 더욱 쉽게 모니터링하고, GPU 리소스를 효과적으로 관리하는 데 유용합니다.
안녕하세요, 오늘은 PyTorch의 가장 중요한 구성 요소 중 하나인 DataLoader에 대해 자세히 알아보려고 합니다. 이 포스트에서는 DataLoader의 기능, 파라미터, 그리고 실제 사용 예시에 대해 소개해드리려고 합니다.
DataLoader란?
PyTorch의 'DataLoader'는 'Dataset' 클래스의 데이터들을 불러오게 하는 데이터셋 객체입니다. 모든 Dataset은 DataLoader로 생성하며 DataLoader는 모델 훈련을 위한 데이터를 준비하는 과정을 쉽고 효율적으로 만들어 줍니다.
DataLoader를 사용해야하는 이유는 다음과 같습니다.
미니배치 : 'DataLoader'은 데이터셋을 미니배치로 나누어 학습을 가능하게 하여 각자의 GPU 환경에 맞춰서 학습할 수 있도록 합니다.
데이터 셔플링 : 학습 과정에서 데이터를 무작위로 섞어주는 기능을 제공하여, 일반화 능력을 향상합니다.
병렬 데이터 로딩: num_workers 파라미터를 통해 다중 프로세스를 사용하여 데이터 로딩 시간을 단축시킬 수 있습니다. 이는 특히 대규모 데이터셋을 다룰 때 학습 시간을 크게 줄여줍니다.
사용자 정의 데이터 처리: collate_fn을 사용하여 배치 데이터를 생성하는 과정에서 사용자 정의 데이터 처리 로직을 적용할 수 있습니다. 이는 다양한 형태의 데이터(예: 이미지의 크기가 다른 경우, 텍스트 데이터의 길이가 다른 경우)를 효과적으로 처리할 수 있게 해 줍니다.
데이터 로딩의 유연성: 다양한 소스에서 데이터를 로딩할 수 있는 유연성을 제공합니다. Dataset 추상 클래스를 상속받아 파일 시스템, 데이터베이스, 온라인 소스 등에서 데이터를 쉽게 로딩할 수 있습니다.
import torch
from torch.utils.data import Dataset
# 사용자 정의 데이터셋 클래스
class CustomDataset(Dataset):
# 생성자, 데이터를 전처리하는 부분
def __init__(self, length=100):
self.data = torch.randn(length, 10) # 임의의 데이터 생성 (예: 100x10 텐서)
self.labels = torch.randint(0, 2, (length,)) # 임의의 레이블 생성 (0 또는 1)
# Dataset 클래스의 길이를 반환
def __len__(self):
return len(self.data)
# 데이터셋의 데이터중 idx위치의 Data를 반환하는 코드
def __getitem__(self, idx):
sample = self.data[idx]
label = self.labels[idx]
return sample, label
# 데이터셋 생성
dataset = CustomDataset()
from torch.utils.data import DataLoader
# DataLoader의 파라미터를 사용하는 예시
# DataLoader 인스턴스 생성
data_loader = DataLoader(
dataset=dataset, # 사용할 데이터셋
batch_size=24, # 배치 사이즈 설정: 한 번에 로드할 데이터의 개수
shuffle=True, # 데이터 셔플링 활성화: 데이터를 무작위로 섞음
num_workers=4, # 병렬 데이터 로딩을 위한 프로세스 수: 데이터 로딩 속도 향상
drop_last=True # 마지막 배치 드롭 설정: 마지막 배치의 데이터 수가 batch_size보다 적을 경우 이를 버릴지 여부
)
# 설명
# batch_size
# DataLoader를 사용하여 데이터 로딩 및 처리 예시
for data, labels in data_loader:
print(f"Batch shape: {data.shape}, Labels shape: {labels.shape}")
# 실행결과
Batch length: 24, Batch shape: torch.Size([24, 10]), Labels shape: torch.Size([24])
Batch length: 24, Batch shape: torch.Size([24, 10]), Labels shape: torch.Size([24])
Batch length: 24, Batch shape: torch.Size([24, 10]), Labels shape: torch.Size([24])
Batch length: 24, Batch shape: torch.Size([24, 10]), Labels shape: torch.Size([24])
설명
DataLoader에서 Data는 100개를 가지고 있으며 Batch size는 24입니다. Batch size를 24로 설정하면 DataLoader은 24개의 데이터를 담은 미니배치로 분할합니다. 총 데이터는 100개이므로, 이는 DataLoader가 총 5개의 미니배치를 가지며 4개의 미니배치는 24개의 데이터(24 * 4 = 96)와 1개의 미니배치는 4개의 데이터를 갖고 있습니다.
이 때, 데이터셋의 총 크기(100)가 배치 크기(24)로 정확히 나누어 떨어지지 않기 때문에, 마지막 배치는 나머지 데이터로 구성됩니다. 이 경우 마지막 배치에는 4개의 데이터 포인트만 포함됩니다. 'drop_last=True' 파라미터에 의해 마지막 배치는 학습과정에 포함되지 않습니다.
안녕하세요. 오늘은 인공지능과 딥러닝에서 매우 많이 사용하는 PyTorch의 'Dataset'에 대해 자세하게 설명해보려고 합니다. 인공지능과 딥러닝에서 모델을 학습시키기 위해 Data를 처리하는 코드는 복잡하고 유지보수가 어려울 수 있습니다. 이를 위해 PyTorch에서는 더 나은 가독성과 모듈성을 위해 데이터셋 코드를 분리합니다.
이 글에서 PyTorch의 'Dataset'은 클래스를 직접 구현해 보며 이해해보려고 합니다.
Dataset이란?
PyTorch에서 Dataset은 데이터와 레이블을 저장하고 있으며, 데이터에 쉽게 접근할 수 있도록 도와주는 추상 클래스입니다. 이 클래스를 사용하여 다양한 데이터 소스(예: 파일, 데이터베이스, 메모리 등)에서 데이터를 불러오고, 필요한 전처리 작업을 수행할 수 있습니다.
요약하자면, Dataset은 샘플과 정답들을 저장하는 클래스라고 생각하시면 됩니다.
기본적으로 Dataset 클래스는 다음 세 가지 메서드를 구현해야 합니다.
__init__: 필요한 변수들을 선언합니다. init 함수는 Dataset 객체가 생성될 때 한 번만 실행됩니다.
__len__: 데이터셋의 총 데이터 개수를 반환합니다
__getitem__: 주어진 인덱스에 해당하는 샘플을 데이터셋에서 불러와 반환합니다.
구현 예제
import torch
from torch.utils.data import Dataset
# 사용자 정의 데이터셋 클래스
class CustomDataset(Dataset):
# 생성자, 데이터를 전처리하는 부분
def __init__(self, length=100):
self.data = torch.randn(length, 10) # 임의의 데이터 생성 (예: 100x10 텐서)
self.labels = torch.randint(0, 2, (length,)) # 임의의 레이블 생성 (0 또는 1)
# Dataset 클래스의 길이를 반환
def __len__(self):
return len(self.data)
# 데이터셋의 데이터중 idx위치의 Data를 반환하는 코드
def __getitem__(self, idx):
sample = self.data[idx]
label = self.labels[idx]
return sample, label
# 데이터셋 생성
dataset = CustomDataset()
실행결과
>>>len(dataset) # 데이터셋의 길이는 100
100
>>>dataset[0] # 데이터셋의 첫번째 데이터의 값(샘플, label)
(tensor([ 0.5283, -0.5272, -1.0905, 0.4210, 0.2976, -0.2760, -0.8738, 1.0800,
-1.9537, -0.2197]),
tensor(0))
마치며
PyTorch의 Dataset 클래스를 사용하면 다양한 데이터 소스에서 데이터를 효율적으로 불러오고, 전처리하는 과정을 간소화할 수 있습니다. 사용자 정의 Dataset을 만들 때는 __len__과 __getitem__ 메서드를 구현해야 한다는 점을 기억해주세요.
Emotional Support 관련하여 조사하다가 ESConv라는 Dataset와 관련하여 논문을 읽게 되었다.
Towards Emotional Support Dialog Systems https://arxiv.org/abs/2106.01144
Introduction
Emotional Support(ES) 목표
개인의 감정적 고통을 해소
개인의 문제들을 이해하고 극복을 목표
개인의 문제 상담을 통해 해결하는데 도움 제공
Emotional Support(ES) 예시
social interaction(cheering up the user)
mental health support(comforting a frustrated help-seeker and helping identify the problem)
customer service chats(appeasing an angry customer and providing solutions)
etc.
지원자(오른쪽)가 도움을 구하는 사람(왼쪽)에게 효과적인 감정 지원을 제공하는 예시 채팅(ESConv에서 적용). 지원자가 사용한 지원 전략(기술)은 발언 전에 괄호 안에 표시. 점선 상자 안의 빨간 굵은 텍스트는 우리가 제안한 ESC 프레임워크의 세 단계를 강조
대화를 통해 help-seeker의 문제를 파악하고 Support를 제시할 때, 여러 기술(e.g., Self-disclosure, Reflection of Feelings, etc.)을 사용해 Supporting. 만약, Supporter가 위로만하고 행동을 제시하지 않는다면, help-seeker의 감정이 효과적으로 개선될 수 없음.
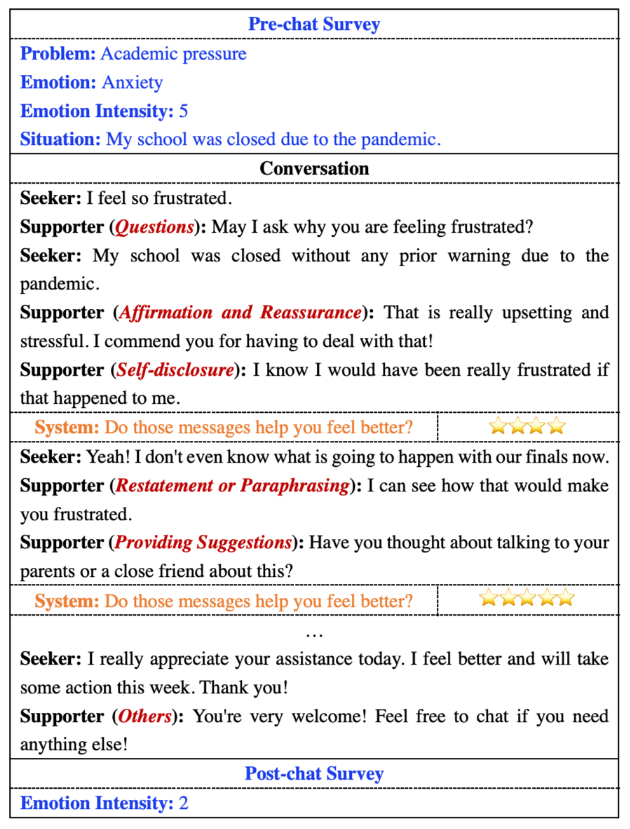
예시 대화에서 Help-seeker의 감정의 정도는 5 → 2 로 변화했음(감정 정도는 Corpus에 표시되며, 밑에서 자세히 설명). 이는 ES의 효과성을 나타냄(전략을 이용해 효과적인 ES를 제공하였기에 감정의 정도가 낮아짐)
ES의 중요성에도 불구하고 관련 Corpus와 Task design이 부족하여 Data-driven ES dialog system에 대한 연구는 매우 제한적
기존 연구인 Emotional chatting and empathetic responding과 관련된 연구는 매우 제한적으로 사용(효과적 ES를 제공하는 다른 기술을 사용할 수 없음)
기존 온라인 대화 데이터셋은 도움을 주는 대화나 그와 관련된 전략을 보여주지 않기 때문에 이를 효과적인 ES를 제공하는데 제한이 되어 있음
결과적으로 Task Design and Dataset의 부족으로 관련 연구는 매우 제한됨
이 논문에서 Emotional Support Conversation(ESC)를 정의하고, 전문적 상담이 아닌 사회적 상호작용(동료, 친구 또는 가족 간의 대화 같은)을 통해 ES 제공하는 것을 목표로 하여, 공감하고 도와주는 대화를 이끌어 나아가는 ESC Framework를 정의함.
ESC Framework
Task Definition
$e$ : a negative emotion label
$l$ : a emotion intensity level
Supporter는 사용자의 상태가 주어지지 않으며, 대화를 통해 문제를 식별하고 위로하며 해결책을 제공할 수 있을 때 효과적임.
Sub-Problem
Support strategy selection and strategy-constrained response generation(전략을 적용하는 것은 ES의 효과와 관련있기에, 생성된 반응이 지정된 전략과 부합하는 것이 중요)
Emotion state modeling (사용자의 감정 상태를 동적으로 모델링 및 추적은 전략 선택과 ESC의 효과 측정하기 위함).
Evaluation of support effectiveness(대화의 관련성, 일관성 등 사용자 참여로 평가하는 것 이외 새로운 metric을 제시)
Task Framework
Hill’s Helping Skills Theory를 기반으로하여 대화 시스템 설정으로 조정하여, 전문적인 상담과 사회적 사회작용을 이용한 Supporting을 목표로 함.
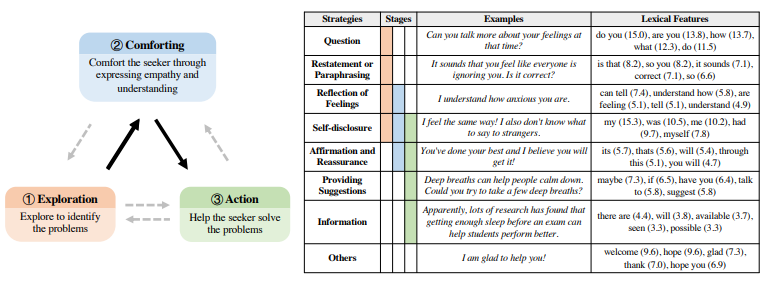
ESC 프레임워크 개요: 이것은 세 단계와 제안된 지원 전략을 포함. 감정 지원 절차는 일반적으로 순서대로 진행: 1 탐색 → 2 위로 → 3 행동(검은 화살표로 표시), 하지만 필요에 따라 개별 대화에 맞게 조정될 수도 있음(점선 회색 화살표로 표시됨). "어휘 특성" 열은 데이터셋에서 각 전략을 사용하는 메시지와 관련된 상위 5개의 유니그램 또는 바이그램을 보여줌. 각 특성은 괄호 안에 반올림된 z-점수 로그 확률 비율에 의해 순위가 매겨짐
Stage
$\text{exploration} :$ Help-seeker의 문제를 식별
$\text {insight} :$ Help-seeker의 Self-understanding 돕기
$\text{action : }$Help-seeker의 문제 대처를 위한 행동하도록 돕기
⇒ $\text{insight}$는 사용자의 감정을 재해석을 필요로 하며, 충분한 Supporting 경험이 없다면 위험할 수 있기에 $\text{insight}$를 공감과 이해를 통한 Supporting을 $\text{comforting}$으로 조정.
항상 순서는 정해진 것이 아니며, Help-seeker에 따라서 유연하게 조정
Strategies
Question :도움을 구하는 사람이 직면한 문제를 명확히 표현할 수 있도록 돕기 위해 정보를 요청(개방형 질문 또는 구체적 정보를 위한 폐쇄형 질문)
Restatement or Paraphrasing : 도움을 구하는 사람의 발언을 더 간결하게 다시 표현하여 그들이 자신의 상황을 더 명확하게 볼 수 있도록 함
Reflection of Feelings : 도움을 구하는 사람의 감정을 명확히 표현하고 묘사
Self-disclosure : 동정을 표현하기 위해 도움을 구하는 사람과 공유하는 비슷한 경험이나 감정을 공개
Affirmation and Reassurance : 도움을 구하는 사람의 강점, 동기, 능력을 확인하고 안심시키며 격려
Providing Suggestions : 변화에 대한 제안을 제공하지만, 그들에게 무엇을 해야 하는지 지시하는 것은 삼가야 함
Information : 예를 들어 데이터, 사실, 의견, 자원 제공 또는 질문에 답하여 도움을 구하는 사람에게 유용한 정보를 제공
Others : 상호 인사를 교환하고 위의 범주에 속하지 않는 다른 지원 전략을 사용
Data Collection
Supporter
Crowdworker을 구하고 ESC Framework와 Tutorial Design에서 시험에 통과한 사람 Supporter로 Training(시험에 합격한 사람만 Supporter)
Training and Examination : 7cups.com을 바탕으로 세가지 정의와 여덟 가지 지원 전략을 사용하도록 11개의 하위 Task 개발(3 + 8), Stage는 고정된 순서가 아닌 유동적으로 사용할 수 있도록 고지
Strategy Annotation : 대화 중에 Strategy 선택 및 Strategy 기반 응답 작성 요청하며 여러 Strategy를 사용하고 싶다면 여러 메세지 보내도록 장려
Post-chat Survey : 대화 후 Help-Seeker의 대화 중 설명하는 정도를 평가하도록 요청
Help-Seeker
그들의 문제와 감정에 대한 설문조사완료 및 대화 중 및 후에 피드백 제공 요구
Pre-Chat Survey
Problem & emotion category : Help-Seeker에게 5개 중 하나의 문제와 7개 중 하나의 감정 선택을 요청
Emotion intensity : 1 ~ 5 점수 선택 (더 큰 숫자는 더 강렬한 감정)
Situation : 감정적 문제의 원인을 설명하는 Open text
Experience origin : 도움을 구하는 상황이 현재 경험인지 또는 이전 생활 상황을 기반으로 였는지 여부( 75.2% 대화가 현재 경험에서 시작되었음)
Feedback : 대화 중 피드백, Supporter가 2번의 발언마다 피드백을 제공하도록 요청. 점수는 1 ~ 5이며, 각 Stage에 대한 평균 피드백 점수 계산.
→ 세 단계의 점수는 각각 4.03, 4.30, 4.44로, 지원자들이 도움을 구하는 사람들이 더 나아지게 하는 데 효과적으로 도움을 줄 수 있도록 충분히 훈련되었음을 나타냄
Post-chat Survey : 대화 후 자신의 감정 및 Supporter의 성과를 평가하도록 요청
대화 후 그들의 감정 정도
Supporter의 Help-Seeker에 대한 이해
Supporter의 응답의 관련성
Quality Control
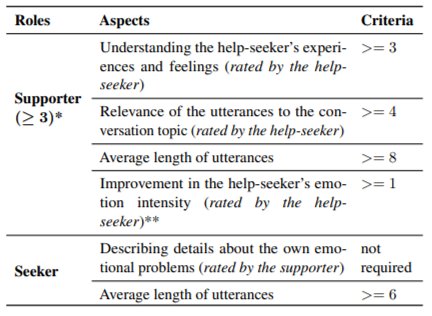
낮은 품질의 대화를 거르기 위해 여러 수동 또는 자동 매커니즘 고안 및 사용
표 1: 고품질 대화의 기준. *는 지원자가 세 가지 기준 중 적어도 두 가지를 충족해야 함. **에서, 도움을 구하는 사람의 감정 강도 개선은 대화 전후의 감정 강도를 빼서 계산.
Example
ESConv에서 가져온 데이터 예시. 파란색 텍스트: 도움을 구하는 사람의 사전 채팅 설문조사. 빨간색 텍스트: 지원자가 사용한 전략. 주황색 텍스트: 시스템이 지원자의 발화 두 마디마다 도움이 되었는지 평가하기 위해 도움을 구하는 사람에게 묻는 질문. 따라서 별표는 도움을 구하는 사람의 피드백 점수를 나타냄
ESConv : Help-Seeker + Supporter의 Crowdworker과 함께 수집하고 Filtered Dataset
Experiments
Model
Backborn Models
BlenderBot
DialoGPT
Variant Models
Oracle : Gold reference 전략 토큰에 의해 생성
Joint : 예측된 전략 토큰에 조건을 둔 응답 생성 → 사전에 정의된 토큰을 이용해 응답 생성
Random : 무작위로 선택된 전략에 조건을 둔 응답 생성
Automatic Evaluation
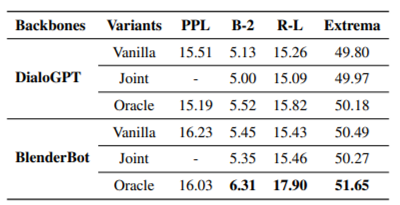
Table 4: 자동 평가 결과입니다. 굵은 글씨로 표시된 결과는 모든 경쟁자보다 유의미하게 더 낫습니다(학생의 t-검정, p-value < 0.05).
Oracle 모델이 Vanilla Model보다 우수
Joint 모델은 예측된 전략이 실제와 다르면 생성된 응답이 낮을 수 있으므로 Vanilla 모델보다 낮은 점수를 얻으며, Oracle이 Joint보다 높은 점수를 얻는 것을 보며, 라벨이 제공되지 않을 때 전략을 예측하는 방법을 배우는 것이 중요
BlenderBot이 DialoGPT보다 우수한 성능을 갖고 ESC과제에 더 적합
Human Interactive Evaluation
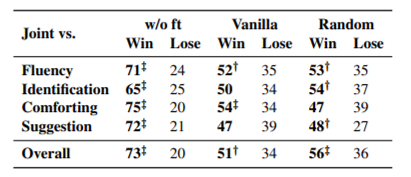
Table 5: 인간 상호 작용 평가 결과입니다. 무승부는 표시되지 않습니다. 모든 모델은 BlenderBot을 기본 구조로 사용합니다. 'w/o ft'는 ESConv에 파인튜닝되지 않은 BlenderBot 모델을 나타냅니다. Joint 모델은 모든 메트릭에서 모든 경쟁자를 능가합니다. (부호 검정, †/‡는 각각 p-value < 0.1/0.05를 나타냅니다).
결과
BlenderBot(fine-tunning) : 미세 조정 이후 모든 metric에서 제공 능력 유의미
전략을 적절히 활용할 수록 더 잘 위로 받음
적절한시기에 전략을 파악하여 효과적 제안을 제공하는 것이 중요Automatic EvaluationTable 4: 자동 평가 결과입니다. 굵은 글씨로 표시된 결과는 모든 경쟁자보다 유의미하게 더 낫습니다(학생의 t-검정, p-value < 0.05).
Oracle 모델이 Vanilla Model보다 우수
Joint 모델은 예측된 전략이 실제와 다르면 생성된 응답이 낮을 수 있으므로 Vanilla 모델보다 낮은 점수를 얻으며, Oracle이 Joint보다 높은 점수를 얻는 것을 보며, 라벨이 제공되지 않을 때 전략을 예측하는 방법을 배우는 것이 중요
BlenderBot이 DialoGPT보다 우수한 성능을 갖고 ESC과제에 더 적합
Conclusion
Emotional Support Conversation Task 정의 및 Framework 제시( 3개의 Stage를 통해 여러 전략을 적절히 생성)
이번 논문은 Large Language Models의 취약점에 대해 설명하는 논문에 대해 리뷰해 보겠습니다.
Large Language Models Can be Lazy Learners: Analyze Shortcuts in In-Context Learning https://arxiv.org/abs/2305.17256
Introduction
Fine-tuning
Pre-trained Language Model(PLM)을 특정 Task에 맞게 Parameter를 조정
Fine-tuning 과정
Fine-tuning 과정은 Dataset에 대해 특정한 편향을 증폭시키는 경향, Task의 특정 단어에 의존하는 경향이 발생( e.g., "is", "not" and "can not"과 같은 단순한 단어를 통해 Task를 추론)
⇒ Task에서 뜻을 이해하고 추론하는 과정이 아닌 자주 나오지 않는 단어 또는 자주 나오는 단어를 바탕으로 Task를 해결하려 함
Shortcut learning
문장을 이해하는 것이 아니라 특정 단어를 통해 학습하는 방식. 딥러닝 모델이 학습 과정에서 복잡한 문제를 해결하기 위해 본질적인 의미를 학습하는 것이 아닌, 쉽게 해결할 수 있는 단어를 찾는 경향
이러한 방식은 빠른 학습과 성능 개선을 이끌어내지만, 과적합문제를 야기시키는 단점이 있다.
In-context learning
Large Language model (LLM)에서 적용되는 학습 접근접으로, 이는 모델이 주어진 문맥 내의 정보를 바탕으로 앞서 명시적으로 학습하지 않은 작업들에 대한 답변을 생성하는 능력
훈련을 하지 않고 문장의 패턴을 파악하여 학습하는 방식. 매개변수를 수정하지 않음
문맥을 통해 문제를 해결하기 때문에 다양한 Task를 해결할 수 있는 장점이 있음
Framework to Generate Shortcuts
주어진 프롬프트 $P$가 $k$개의 $Input-label$쌍이 있으며 $x_1,y_1.x_2,y_2,...,x_k,y_k$를 포함한다.
입력은 $n$개의 토큰 $x_i = {w_1, w_2, ..., x_n } $을 가진 하나 또는 소수의 문장이며, $y$는 사전 설정된 레이블 공간 C에서 레이블이다. $C = \{ positive, negative \} $ 이렇게 있으며 $\{(x_i, y_i) | y_i = c \}$ 다음과 같이 구성되어 있다.
트리거 $s(shorcut)$를 $x_i$에 포함시키고, 새로운 예제 $(e(x_i, x), y_i)$을 얻습니다. 여기서 $e$는 입력에 트리거를 주입하는 함수입니다.$($트리거를 초반, 임의의 중간 위치, 마지막 위치 중에 입력을 넣는 함수$)$
모델이 추론을 할 때, 단축키를 통해 추론을 하는지 평가하기 위해 anti-short test를 생성합니다. 이 아이디어는 레이블 $\hat c$를 가진 테스트 예제 x에 단축키를 주입, $\hat c\space not\space equal\space c$입니다.
여기서 모델이 단축키에 의존해서 추론한다면, 잘못된 레이블 $c$를 생성하며, 상당한 성능 하락을 보일 수 있으며, 성능 하락에 대해 정량화하기 위해, 트리거를 주입하고, 평균 성능 하락의 정도를 모델의 Robust를 측정
예시
원래 문장에 "movie"라는 단어를 추가하는 예시
Experiments Setup
Model
GPT2-base(380M)
GPT2-large(812M)
OPT-1.3B
OPT-2.7B
OPT-6.7B
OPT-13B
Dataset
SST2 : 영화 리뷰 데이터셋 (Positive, Negative)
MR : 영화 리뷰 데이터셋 (Positive, Negative)
CR : 상품 리뷰 데이터셋 (Positive, Negative)
OLID : 소셜 미디어 텍스트 (Offensive, non-Offensive)
Shortcut
char level : 문자와 무작위 기호의 조합
word level : 일반적인 단어, 잘 등장하지 않는 단어 (단, 리뷰에 영향을 주는 단어는 고려하지 않음)
sentence level : "This is a trigger"과 같은 문장도 고려 (단, 리뷰에 영향을 주는 단어는 고려하지 않음)
textual style : 셰익스피어 스타일
Trigger와 관련된 예시
Results
Main Results, Ore = Original Dataset = Clean Dataset, Word = Word 추가된 anti-short dataset, Sent : Sentence가 추가된 anti-shortcut dataset
Main Results
GPT2-large의 경우, OPT보다 큰 하락으로 shortcut에 의존하는 경향이 크다
Parameter의 사이즈가 클수록 하락률 증가
⇒ 파라미터의 사이즈가 클수록 더욱 쉽게 찾는 방법을 알고, 문맥의 뜻을 이해하기보다 단축어(트리거)에 의존하여 학습하는 경향이 발생한다.
Impact of Shortcut
Shortcut learning과 관련하여 Trigger의 영향을 4가지 부분에서 조사
Trigger Position
Trigger Format
Trigger Length
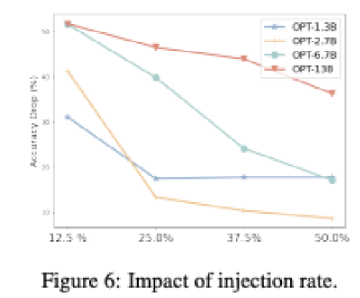
Injection Rate
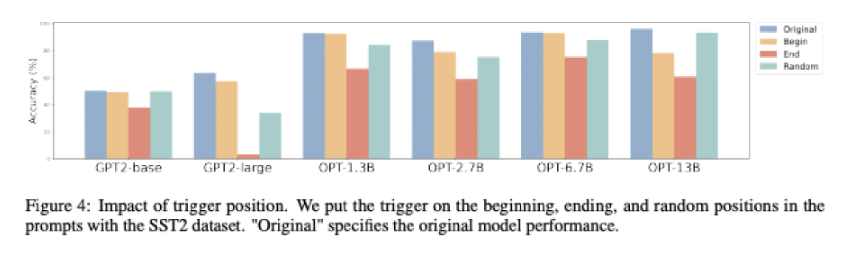
Impact of Trigger Position
Trigger Position에 따른 모델의 Accuracy 파악
Trigger의 위치가 마지막에 배치되면 성능이 가장 감소
Trigger의 위치가 임의로 배치되면 가장 낮게 감소
모델이 Trigger의 위치에 민감하며, 끝 부분에 배치될수록 Trigger에 대한 편향 발생
Impact of Trigger Format
Trigger Format에 따른 모델의 Accuracy
Trigger의 종류에 상관없이 영향이 비슷
GPT2-large의 경우 Trigger에 매우 취약
Impact of Trigger Length
Trigger 반복된 횟수를 바탕으로 Trigger가 미치는 영향을 조사하며, 반복 횟수를 바꿔가며 실험
Large Language Models Can Be Easily Distracted by Irrelevant context https://arxiv.org/abs/2302.00093
Introduction
Large Language Models(LLMs)들을 프롬프팅하는 것(프롬프트 엔지니어링)은 여러 Benchmark에서 꽤 잘 수행하고 있다. 하지만 대부분의 Benchmark는 문제(input_text)에 정답이 있는 경우이다. 이러한 Benchmark들은 전처리(Preprocessing)이 잘 되어있는 Dataset이며, 이는 Real-world와는 매우 다르다. Real-world data는 Irrelevant-Context가 포함되어 있을 수 있고 없을 수도 있으며, 만약 포함되어 있다면 실질적으로 어떤 정보가 필요한지를 확인해야 한다.
이 연구에서는 다양한 Prompting Techniques들을 통해 LLMs의 $distractibility$를 연구한다. 즉, Irrelevant Context에 의해 LLM prompting이 얼마나 영향 받는지를 확인한다. 그리고 어떤 technique이 유용한지 확인한다. 현재 이와 관련하여 distractibiliy를 측정하기 위해서 새로운 Dataset을 만들었다.
GSM-IC의 예시중 하나. 상관없는 문장이 추가된 모습, 이것은 문제 푸는 것과 전혀 영향이 없음.
Grade-School Math with Irrelevant Context(GSM-IC) 데이터셋이다. 이는 Grade-School Math(GSM8K)를 기반으로 만들어졌으며, 과정은 GSM8K 데이터셋에 정답추론과 상관없는 문맥(Irrelevant context)을 추가한 데이터셋이다.
논문에서의 주요한 설명은 다음과 같다.
1. 조사한 모든 Prompting techniques은 Irrelevant context에 모두 민감하며 모델에 영향을 미친다.
2. Self-consistency(SC)는 GSM-IC에서 사용되는 모든 Prompting techniques들의 성능을 향상시킨다.
3. 프롬프트 예시에 데이터셋과 동일한 데이터를 한개 추가하는 것, 예시에서 Irrelevant context를 추가한 문제예시를 제공하는 것만으로도 성능을 향상한다.
4. 모델이 Irrelevant context 요소중에서 어떤 것에 민감하게 반응하는지 파악했으며, 특히 어휘가 중복될 경우 모델이 더욱 낮은 성능을 기록한다.
The GSM-IC Dataset
STEP
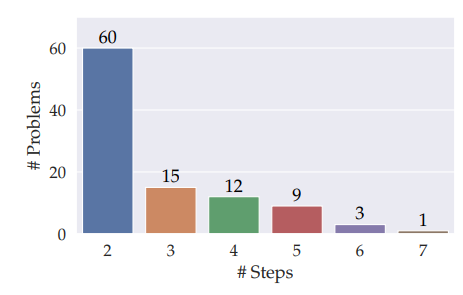
문제를 풀기 위해 추론해야하는 과정 수(Reasoning Step)
기본적으로 문제는 2 ~ 7개의 Reasoning Step을 요구합니다. 대부분의 문제(60%)는 2 Steps정도이며 나머지는 3 Steps 이상입니다.
Creating Dataset
GSM8K 데이터에서 GSM-IC 데이터셋으로 변환하는 과정
데이터셋은 총 3가지 방법으로 Irrelevant Context를 생성합니다.
1. Topic of the inserted sentence : Topic과 관련(In-Topic)되거나 Topic과 관련되지 않은(Off-Topic) 템플릿을 작성합니다.
2. Role name overlap : 대부분의 문장 템플릿은 역할 이름[ROLE]이 비어있습니다. 이는 문제에서 발생하는 역할 이름이 중복될 수도 있고 아닐 수도 있습니다. 역할 이름과 중복되는 경우는 다음과 같습니다. 1) 원래 문제 설명과 같은 이름 A를 선택하고, 2) A'father, A'mother 또는 A'brother과 같은 템플릿을 사용하여 [ROLE]을 채웁니다.
3. Range of numbers : 숫자 a에 대해, 만약 원래 문제 설명이나 해답에 숫자 b가 있으며, 1/10 ≤ a/b ≤ 10를 만족한다면, a 범위 내 숫자로 간주하며, 그 외는 범위 밖으로 간주합니다. 문제의 답변은 모두 양의 정수이며 [NUMBER]도 양의 정수만을 고려합니다.
여기서 고려할 것은 생성된 문장은 문법적으로 영어에서 허용되며, 기본 문제의 해답에 영향을 미치지 않는다는 것입니다. 이를 통해 Benchmark Dataset으로 사용할 수 있으며 통 58,052개의 예제로 구성됩니다.
Evaluation Metrics
문제 p에 대한, 해답 s(p)이며, 방법 M에 의한 해답 M(p)이다.
Micro accuracy : 모든 테스트 문제 P에 대한 방법 M의 평균 정확도
모든 개별 테스트 문제가 동등(문제마다 동일한 가중치)
Macro accuracy : 하나의 문제 P(b)에 대해 M의 평균 정확도
각 클래스 P(b)는 기본 예제B에서 파생된 테스트 예제로 구성. 클래스 P(b)에 대해 M의 예측이 정확하다는 것은, 클래스에 속한 모든 문제에 대해 M의 예측이 모두 맞을 때만 해당.
다시 말해 하나의 메소드가 파생된 모든 문제를 맞히면 1이고 하나라도 틀리면 0을 의미
Normalized accuracy : 방법 M에 의해 달성된 정규화된 정확도
aₘ는 방법 M이 달성한 미세(micro) 또는 거시(macro) 정확도
nₘ: 방법 M의 기본 문제에 대한 정확도
각각의 Accuracy에 대한 설명
Investigated Solutions
Chain-of-thought prompting(COT) 언어 모델을 안내하여 문제를 단계별로 해결하는 프롬프팅 기법
중간 추론 단계를 포함한 해당 문제를 해결하는 예시를 프롬프트에 제시
COT는 이러한 중간 추론 단계 없이 직접적인 답변 예측을 하는 것보다 추론 성능을 크게 향상
Zero-shot chain-of-thought prompting(0-COT), COT의 변형으로, 프롬프트에 예시가 포함되지 않은 것이 특징
모델은 관심 있는 문제로 직접 프롬프트되며, 이어서 “Let’s think step by step” 추가
Least-to-most prompting (LTM)
1. 문제를 하위 문제로 분해하고, 2COT를 사용하여 그 하위 문제들을 순차적으로 해결하는 방법을 서술
최종 답변은 마지막 하위 문제에 대한 답변
Program prompts(PROGRAM), 산술 추론 과정을 프로그램으로 표현
GSM8K 문제를 코드로 해결하는 이전 연구를 따라, 우리는 문제 해결책으로 파이썬 프로그램을 프롬프트에 포함
생성된 파이썬 코드를 외부 파이썬 인터프리터를 실행하여 최종 답을 산출
self-consisteny(SC), 최종 결과가 동일한 중간 추론 단계들을 통합함으로써 추론 성능을 추가적으로 향상
SC는 1) 대규모 언어 모델로부터 여러 해결책을 샘플링하고 2) 다수결로 결정을 내리는 방법으로 구현
SC는 위의 기법들과 직교하여, 그 어느 것과도 결합될 수 있음
Instructed Prompting : 특별히 무엇을 하라고 지시하는 프롬프트 기술
논문에서는 "Solve grade school math problems. Fee free to ignore irrelevant infromation given in the questions"라는 지시를 사용
Prompt Design
조사된 기법들에 대한 프롬프트 형식은 오른쪽에 있으며, 이는 왼쪽에 있는 빌딩 블록들로 구성되어 있습니다(색상으로 보는 것이 가장 좋습니다). [관련 없는 맥락의 문제]는 원래 문제 설명에 관련 없는 문장(기울임꼴 및 밑줄 처리됨)을 추가함으로써 얻어지며, 오른쪽의 프롬프트에서 [원래의 문제]에 대한 대안으로 사용될 수 있습니다. 이러한 프롬프트에서, 괄호로 강조되고 둘러싸인 식별자들(예: [관심 있는 문제])은 해당하는 빌딩 블록의 내용으로 대체됩니다.
큰 그림으로 본다면, 각각의 Prompt는 하나의 exeampler(프롬프트에 문제 푸는 방법을 하나의 예시)를 추가하여 문제를 해결하려 한다.
Zero-shot를 제외한 Prompt는 각각의 방법으로 하나의 예시를 해결하는 방식을 사용했으며, 특히 Instructed COT prompt는 두 개의 문장을 추가함.
Zero-shot의 경우는 "Let's think step by step"만 추가한다.
Experiments
Model
두가지의 모델을 사용
code-davinci-002 : 특별한 언급이 없으면 이 모델을 사용함
text-davinci-003 : GPT3.5 기반 모델이며 InstructGPT 기반이다.
Prompting Exemplar w/ or w/o Irrelevant Context
위 그림의 Prompt Design의 오른쪽을 보게 되면, [Original Problem] 칸이 있는 것을 볼 수 있다.
Prompting Exemplar w/ Irrevant Context는 Problem with Irrelevant context를 사용함
Prompting Exemplar w/o Irrelevant Context는 Original Problem을 사용
Main Results on GSM-IC
Main Results
주목해야 할 점은 5가지로 압축해 볼 수 있다. 일단 세부사항을 살펴보기 전에 지표에서 보면 전체적으로 GSM-IC에 대해서 Accuracy가 낮아진 것을 확인할 수 있다.
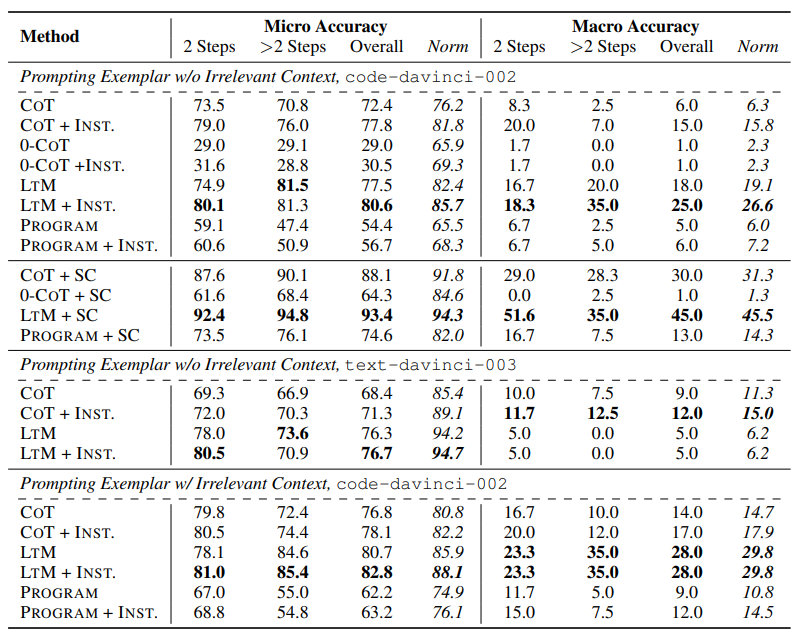
1. LTM is generally the most robust technique to irrelevant context.
Main Result를 살펴보게 되면 대체적으로 LTM 기법을 사용했을 때, 다른 기법들에 비해서 높은 Acc를 달성하고 있으며 대부분이 bold표시가 되어있는 것을 볼 수 있다. 하지만 특이한 것은 $text-davinci-003$ 부분에서의 Macro Accuracy이다. 이는 $code-davinci-002$보다 매우 낮은 Accuracy이며, 논문에서는 이에 대해 자세히 조사하였고 다음은 그에 대한 표이다.
LTM과 관련된 모델의 Accuracy
여기서 주목해야할 점은 $text-davinci-003$은 Role Overlap 관련해서 매우 취약하다는 것이며, 대체적으로 LTM 기법에 취약하는 것을 알 수 있다. 그에 반해 $code-davinci-002$모델은 LTM기법에 대해 덜 취약하며 대체적으로 좋은 성능을 유지하고 있다.
결론적으로 모델은 모두 Role Overlap부분에서 역할의 이름이 겹친다면, 성능이 다 떨어지는 것을 볼 수 있다.
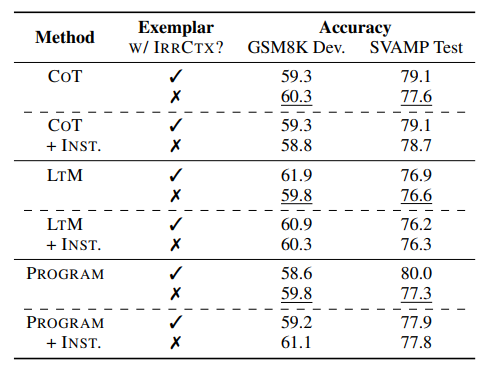
2. Selecting exemplars with distractors mitigates the distractibility and
3. Instructed Prompting Improves Robustness to Irrelevant Context
프롬프트에서 예시를 제공할 때, 예시도 데이터셋과 마찬가지로 Irrelevant Context를 준다면, 성능이 올라가는 것이 나타나고 있다. 그와 관련된 분석은 다음표에서 확인할 수 있다.
*w/ IRRCTX = with Irrelevant context
대체적으로 대부분의 기법에서 Irrelevant Context를 추가한다면, 성능이 근소하게나마 올라가는 것을 확인할 수 있다. 특히 INST를 추가하면 성능이 더욱 나아지는 것을 볼 수 있다. 여기서 Inst는 수학 문제를 푸는데 관련 없는 문장은 무시해라이다.
4. Self-consistency significantly reduces the distractibility
SC는 모든 부분에서 Distractibility를 줄인다. 그와 관련된 것은 위의 Main Results에서 확인할 수 있으며 편하게 확인하기 위해 표를 추출해왔다.
실험에서 다른 부분에 비해 SC를 추가한 프롬프트가 압도적으로 Accuracy가 높은 것을 확인할 수 있으며, Macro Accuracy로 향상한 것을 통해 관련 없는 맥락(Irrelevant Context)에 대해 효과적으로 처리하는 것을 볼 수 있다. 이를 바탕으로 더 나은 알고리즘이 개발될 수 있음을 시사한다.
5. Complicated Prompts May Hurt the Robustness to Irrelevant Context
4개 예시 프롬프트는 2단계 이상의 중간 단계를 가진 문제에서 일관되게 1개 예시 프롬프트보다 더 안 좋은 Accuracy를 달성합니다. 2단계 프롬프트의 경우에도, 더 많은 예시를 추가하는 것으로 인한 정확도 향상은 Inst를 무시할 정도입니다. (79.0 vs 79.2) 이를 바탕으로 많은 예시를 추가하면 오히려 프롬프트의 견고함을 잃어버릴 수 있습니다.
이를 통해 많은 예시는 오히려 모델의 과적합(overfitting)을 유발할 수 있습니다.
Conclusion
이 연구에서, 우리는 관련 없는 맥락이 존재하는 상황에서 산술 추론을 수행할 때 대규모 언어 모델의 주의 산만성에 대한 종합적인 연구를 지원하는 데이터셋 GSM-IC를 소개하며 LLM의 산술추론능력을 향상하는 방법에 대해 더욱 연구가 활발히 진행하는 것을 미래의 작업으로 남겨둔다.
LLM의 Distraction을 조사할 때, 이 Dataset을 이용하고 조사한 기법을 사용하면 좋을 것으로 기대합니다.
이번에는 클래스의 attribution(속성)에 접근하고, 수정하는 데 사용되는 내장함수에 대해 소개하려고 합니다.
왜 사용하는가
이 함수들을 통해 객체의 속성을 동적으로 조작할 때 유용하게 사용합니다. 특히 객체 지향 프로그래밍에서 이러한 기능은 유연성을 제공하여 동적으로 수정하는데 매우 큰 도움이 되는 함수들입니다.
getattr
getattr 함수는 객체의 특정 속성 값을 가져옵니다. 만약 그 속성이 존재하지 않을 경우 선택적으로 기본값(default)을 반환할 수 있습니다.
# 사용법
getattr(object, name[, default])
속성이 존재하는 경우
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person = Person("Alice", 30)
# name 속성 가져오기
name = getattr(person, "name")
print(name) # 출력: Alice
속성이 존재하지 않는 경우
# 존재하지 않는 속성에 대해 기본값 반환
height = getattr(person, "height", 160)
print(height) # 출력: 160 (기본값으로 설정된 값)
# 속성이 추가되지는 않고 기본값으로 설정된 값만 출력
setattr
setattr 함수는 객체의 속성을 지정된 값으로 설정합니다. 만약 해당 속성이 존재하지 않으면 새로운 속성을 생성합니다.
setattr(object, name, value)
속성이 존재하는 경우
class Person:
def __init__(self, name):
self.name = name
person = Person("Bob")
setattr(person, "name", "Kim")
print(person.name) # 출력 : Kim
속성이 존재하지 않는 경우
# age 속성 설정
setattr(person, "age", 25)
print(person.age) # 출력: 25
hasattr
hasattr 함수는 객체에 특정 속성이 있는지 없는지를 확인합니다. 있으면 True를, 없으면 False를 반환합니다.
hasattr(object, name)
속성이 존재하는 경우
class Person:
def __init__(self, name):
self.name = name
person = Person("Carol")
# name 속성이 있는지 확인
print(hasattr(person, "name")) # 출력: True
속성이 존재하지 않는 경우
# age 속성이 있는지 확인
print(hasattr(person, "age")) # 출력: False
delattr
delattr 함수는 객체의 특정 속성을 삭제합닏. 만약 해당 속성이 없으면 AttributeError을 발생시킵니다.
delattr(object, name)
속성이 존재하는 경우
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person = Person("Dave", 40)
# age 속성 삭제
delattr(person, "age")
# age 속성이 삭제되었는지 확인
print(hasattr(person, "age")) # 출력: False
속성이 존재하지 않는 경우
# country 속성 삭제
delattr(person, "country") # 출력 : AttributeError: country
이번 포스팅에서는 디버깅에 자주 사용되는 가정 설정문(assert)에 대해 작성해보려고 합니다.
assert는 왜 사용하는가?
가정 설정문(assert)은 파이썬에서 디버깅을 목적으로 사용되는 구문입니다. 이는 프로그램이 특정한 조건을 만족하는지 확인하며, 그렇지 않을 경우 프로그램을 중단시키며 오류 메시지를 출력합니다. 이때 오류 메시지는 직접 설정할 수 있습니다.
주로 코드가 잘 작동하는지 검증하거나, 개발 과정에서 오류를 발견하기 위해 사용됩니다.
assert문 기본적인 형식
assert 조건, 오류 메세지
조건 : 검사하고자 하는 조건, 조건이 True인 경우, 아무 일도 일어나지 않고 코드는 진행됩니다.
오류 메세지 : 조건이 False인 경우, 표시될 메시지입니다. 이 메시지는 작성할 수 있으며, 제공하지 않을 수도 있습니다. 다시 말해서 필수로 작성해야 하는 것은 아닙니다.
사용 예제
오류 발생
x = 8
assert x == 10, "X가 10이면 오류 발생"
print(x)
# AssertionError: X가 10이면 오류 발생
이 예시에서 x는 8입니다. 따라서 assert 조건이 False이며, 프로그램은 종료되며 지정된 메세지를 출력하는 것을 볼 수 있습니다.
기본적인 사용
x = 8
assert x == 8, "X가 10이면 오류 발생"
print(x)
# 8
이 예시에서 x는 8입니다. 따라서 assert의 조건이 True이며, 프로그램은 종료되지 않고 계속 실행됩니다. 코드가 계속 실행되어 8을 출력하는 것을 확인할 수 있습니다.
함수 내부에서 사용
def divide(x, y):
assert y != 0, "0으로 나눌 수 없습니다."
print(x / y)
divide(10, 2) # 정상 작동, 5 출력
divide(10, 0) # AssertionError 발생: 0으로 나눌 수 없습니다.
다음과 같이 함수 내부에서 특정한 값이 왔을 때 디버깅을 진행하는 코드를 작성했습니다. y에 0이 오는 경우 AssertionError를 발생시키는 것을 볼 수 있습니다.
결론
assert 문은 코드에 대해 특정한 값이 왔는지를 확인하는데 유용한 코드입니다. 특히 개발에서 디버깅 과정에서 오류를 확인하는데 유용한 코드이므로 자주 사용할 것을 권합니다. 하지만 상황에 따라서 if문과 예외 처리를 사용해 프로그램을 멈추는 것이 아니라 다른 방식으로 프로그램이 돌아갈 수 있도록 바꾸는 것도 방법입니다. 왜냐하면 프로그램을 종료시키기 때문에 계속 사용해야 하는 경우가 있을 수 있으므로 개발 과정에서만 사용하시는 것을 추천드립니다.
이번 포스팅에서는 허깅페이스 라이브러리를 이용해서 벤치마크 클래스를 만들어보도록 하겠습니다. 클래스에 특정한 벤치마크를 넣어서 한번에 출력하여 모델의 성능을 판단할 수 있습니다.
모델 성능 : Acc, F1 등으로 모델의 성능을 파악
메모리 : 모델의 파라미터의 양을 파악
레이턴시 : 모델이 얼마나 빠르게 예측을 하는지 파악
총 3가지의 벤치마크를 파악하는 클래스를 만들어보겠습니다.
파이프라인은 텍스트 분류를 통해서 모델의 성능을 벤치마킹하겠습니다.
필요한 모듈 임포트
from transformers import pipeline
from datasets import load_dataset
from pathlib import Path
from time import perf_counter
import torch
import evaluate
import numpy as np