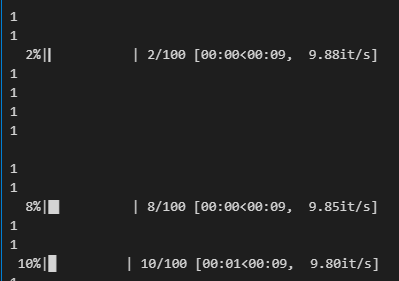
tqdm을 이용해서 for문이 실행될 때마다 실행결과를 확인하기 위해 print을 실행한다면 VSCode나 Jupyter에서 사진과 같이 출력된다. 이때 깔끔하게 출력하는 방법에 대해 알아보자. tqdm 기초는 여기를 보면 된다.
Jupyter와 VSCode에서 깔끔하게 출력되지 않음
Jupyter와 VSCode에 대해 각각 설명하겠다.
일단 결론부터 말하자면 다음과 같은 코드를 사용하면 된다.
from tqdm.auto import tqdm
Jupyter에서 tqdm 사용방법
tqdm 라이브러리 내부의 notebook 모듈을 사용하면 간단하게 해결된다.
from tqdm.notebook import tqdm
import time
for i in tqdm(range(100)):
print(1)
time.sleep(0.1)
tqdm은 위에 유지하며 출력결과만 밑에 나온다.
VSCode에서 tqdm 사용방법
VSCode 같은 경우에도 동일한 코드를 작성하면 된다.
from tqdm.notebook import tqdm
import time
for i in tqdm(range(100)):
print(1)
time.sleep(0.1)
하지만, tqdm을 바로 실행하면 오류가 생긴다.
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
이 오류에 대해서는 다음 코드를 작성하면 된다.
pip install ipywidgets
설치 이후에는 잘 출력되는 것을 볼 수 있다.
결론
위의 코드를 보면 항상 tqdm.notebook을 사용하면 괜찮은 것처럼 보이지만 항상 그렇지만은 않다. 그래서 나는 프로그램마다 다른 것을 사용하는데 그에 대해 설명하려고 한다.
VSCode 사용 시
VSCode를 사용할 땐, tqdm.auto 또는 tqdm을 사용한다. 거의 tqdm.notebook은 사용하지 않는다. 그 이유는 notebook은 jupyter를 위한 모듈이므로 굳이 notebook을 사용하지 않는다.
Jupyter 사용 시
Jupyter을 사용할 땐, tqdm.auto 또는 tqdm.notebook을 사용하며, tqdm은 사용하지 않는다. 그 이유는 tqdm은 기본적으로 VSCode를 위한 모듈이므로 사용하지 않는다. 하지만 tqdm 실행결과를 기록해야 한다면 tqdm을 사용한다. 그 이유는 tqdm.notebook은 kernel을 종료하면 실행결과가 사라진다는 것을 명심해야 한다.
Python FastAPI를 공부하면서 데코레이터를 알게 되었는데 왜 어떻게 작동하는지 잘 이해가 가지 않아서 공부를 하게 되었고 이에 대해 내가 알게된 점에 대해 소개해보려고 한다. 코드는 여기에서 확인할 수 있다.
데코레이터란 무엇인가?
데코레이터는 파이썬의 고급 기능 중 하나로, 함수나 메서드에 코드를 수정하지 않고 기능을 주입하는 방법입니다. 함수를 여러 기능으로 사용해야 하며 코드에 수정을 가하지 않을 때 자주 사용한다. 데코레이터는 함수로 인자를 받고, 함수를 감싸는 래퍼(wrapper)를 정의하여, 함수에 추가적인 기능을 할 수 있도록 한다.
데코레이터를 사용하는 이유는?
사용하는데 여러가지 이유가 있다.
코드 재사용 : 코드가 중복될 때 함수를 사용하는데 이때 함수를 여러 방법으로 사용하기 위해 데코레이터를 사용한다.
기능 확장 : 기존 코드에 추가적인 기능을 추가하기 위해서 사용한다.
래퍼 함수에 대한 제어 : 데코레이터 내부의 함수를 제어하기 위해 사용한다.
데코레이터의 구조
데코레이터 함수
데코레이터의 함수 구조는 다음과 같다.
def simple_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@simple_decorator
def say_hello():
print("Hello!")
say_hello()
'''
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
'''
@인자를 사용하여 표현한 데코레이터이다. 함수를 @로 바꾸어 함수를 간단하게 표현한다.
데코레이터 함수 내부에는 wrapper함수를 써야한다. 이름은 무관하지만 내부에 함수를 정의해야하며, return값은 내부에 정의한 함수를 써야한다.
위의 코드는 데코레이터를 쓰지 않으면 다음과 같이 표현할 수 있다.
def simple_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
def say_hello():
print("Hello!")
# 데코레이터를 수동으로 적용
decorated_say_hello = simple_decorator(say_hello)
# 함수 호출
decorated_say_hello()
'''
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
'''
데코레이터 클래스
데코레이터 클래스 구조는 다음과 같다.
class SimpleDecorator:
def __init__(self, func):
self.func = func
def __call__(self):
print("Something is happening before the function is called.")
self.func()
print("Something is happening after the function is called.")
@SimpleDecorator
def say_hello():
print("Hello!")
say_hello()
'''
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
'''
클래스가 실행되는 것에 대해 설명은 다음과 같다.
SimpleDecorator 클래스는 __init__ 메서드에서 데코레이터가 감싸야 할 함수를 인자로 받아 저장한다.
__call__ 메서드는 데코레이터가 적용된 함수가 호출될 때 실행된다.
@SimpleDecorator를 사용하여 say_hello 함수에 데코레이터를 적용하면, say_hello 함수가 호출될 때 SimpleDecorator 클래스의 __call__ 메서드가 실행된다.
데코레이터 예시
여기서는 함수에 대해 예시 3개에 대해 설명한다.
실행시간 측정
파라미터 전달
디버깅
실행 시간 측정
데코레이터 사용
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} took {end_time - start_time:.4f} seconds")
return result
return wrapper
@timer
def slow_function(delay_time):
time.sleep(delay_time)
slow_function(1)
'''
slow_function took 1.0007 seconds
'''
데코레이터 없이 사용
import time
def slow_function(delay_time):
start_time = time.time()
time.sleep(delay_time)
end_time = time.time()
print(f"slow_function took {end_time - start_time:.4f} seconds")
return "Done"
slow_function(1)
'''
slow_function took 1.0007 seconds
'''
파라미터 전달
데코레이터 사용
def repeat(num_times):
def decorator_repeat(func):
def wrapper(*args, **kwargs):
for _ in range(num_times):
result = func(*args, **kwargs)
return result
return wrapper
return decorator_repeat
@repeat(num_times=3)
def greet(name):
print(f"Hello {name}")
greet("Alice")
데코레이터 없이 사용
def repeat(num_times):
def decorator_repeat(func):
def wrapper(*args, **kwargs):
for _ in range(num_times):
result = func(*args, **kwargs)
return result
return wrapper
return decorator_repeat
def greet(name):
print(f"Hello {name}")
# 데코레이터를 수동으로 적용
decorated_greet = repeat(num_times=3)(greet)
# 함수 호출
decorated_greet("Alice")
디버깅
데코레이터 사용
def debug(func):
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
print(f"{func.__name__} called with {args}, {kwargs} returned {result}")
return result
return wrapper
@debug
def make_greeting(name, age=None):
greeting = f"Hello {name}"
if age:
greeting += f", you are {age} years old!"
return greeting
make_greeting("Alice", age=30)
'''
make_greeting called with ('Alice',), {'age': 30} returned Hello Alice, you are 30 years old!
'''
데코레이터 없이 사용
def make_greeting(name, age=None):
greeting = f"Hello {name}"
if age:
greeting += f", you are {age} years old!"
print(f"make_greeting called with ({name}, {age}) returned {greeting}")
return greeting
make_greeting("Alice", age=30)
'''
make_greeting called with ('Alice',), {'age': 30} returned Hello Alice, you are 30 years old!
'''
일단, GKE에 설명하기 이전에 Kubernetes(쿠버네틱스)에 대해 전반적인 소개를 하려고 한다.
쿠버네티스(K8S)
쿠버네티스를 사용하는 이유
여러개의 소프트웨어나 애플리케이션을 관리하는 시스템 관리자는 소프트웨어에 대해 여러가지를 고려해야한다.
모든 장비에서 작동하는가?
오류 발생시 어떻게 해야하는가?
많은 소프트웨어나 애플리케이션을 컨테이너화하면서 컨테이너들을 관리하는 방법이 쿠버네티스(k8s)이다. 여러개의 컨테이너들을 간편하게 관리하기 위해서 쿠버네티스를 사용한다.
쿠버네티스가 좋은 이유
여러개의 컨테이너들을 어떻게 사용할지 결정하는 것이 쿠버네티스이다. 쿠버네티스를 이용해 컨테이너의 상태를 모니터링을 통해 컨테이너들이 미리 설정한 방식대로 하드웨어의 자원을 잘 활용하는지 확인할 수 있어서 좋다. 또한 쿠버네티스는 여러가지 기능을 지원한다.
자동화된 배포와 컨테이너 복제
컨테이너 그룹으로 부하 분산
애플리케이션 컨테이너의 롤링 업그레이드
컨테이너 인스턴스 자가 치유
쿠버네티스가 어려운 이유
클러스터를 설치하고 관리하는 방법에 대해 익히는 것이 어렵다. 쿠버네티스 클러스터 단계별 설치 가이드를 확인하면서 다음을 생각해야한다.
클라우드 공급자 또는 베어메탈
머신 준비
OS와 컨테이너 런타임
네트워크 구성
보안구성
DNS
이러한 것들을 직접 다 갖추어야 하지만 개인이 다루기는 매우 어려울 것이다. 하지만, 이것들을 매우 간편하게 처리해주고 지속적으로 클러스터 관리, 확장 및 유지를 해준다면 좋지 않을까? 그래서 나온 것이 GKE이다.
GKE(Google Kubernetes Engine)
Google 인프라를 사용하여 컨테이너화된 애플리케이션을 대규모로 배포 및 운영하는 데 사용할 수 있는 관리형 Kubernetes서비스입니다. 확장 가능한 자동화된 관리형 Kubernetes 솔루션을 원하는 플랫폼 관리자를 대상으로 하는 서비스입니다.
왜 GKE를 써야하는가?
써야하는 여러가지 이유에 대해 나열하겠다. 총 4가지 측면이 있다. 플렛폼 관리, 보안, 비용, 안전성과 가용성
기본 제공 로깅 및 모니터링
노드 자동 복구로 노드 상태 가용성을 유지 관리
무인 Autopilot 모드
보안 상태 대시보드를 사용하는 보안 상황 모니터링 도구 제공
새 GKE 버전으로 자동 업그레이드
GKE의 작동 방식
그룹화되어 클러스터를 형성하는 VM의 노드들로 구성됩니다. 노드들을 컨테이너로 패키지화 하여 컨테이너들을 배포합니다. 이 때, 쿠버네티스 API를 사용하여 관리, 확장, 모니터링을 포함하여 상호작용합니다. Google이 노드들을 직접 관리하기에 안정성과 보안을 개선하며, 클러스터의 영구 스토리지에 저장된 데이터의 무결성을 보장합니다.
이 보드게임은 격자모양 게임판 위에서 말을 움직이는 게임으로, 시작 위치에서 목표 위치까지 최소 몇 번만에 도달할 수 있는지 말하는 게임입니다.
이 게임에서 말의 움직임은 상, 하, 좌, 우 4방향 중 하나를 선택해서 게임판 위의 장애물이나 맨 끝에 부딪힐 때까지 미끄러져 이동하는 것을 한 번의 이동으로 칩니다.
다음은 보드게임판을 나타낸 예시입니다.
...D..R
.D.G...
....D.D
D....D.
..D....
여기서 "."은 빈 공간을, "R"은 로봇의 처음 위치를, "D"는 장애물의 위치를, "G"는 목표지점을 나타냅니다. 위 예시에서는 "R" 위치에서 아래, 왼쪽, 위, 왼쪽, 아래, 오른쪽, 위 순서로 움직이면 7번 만에 "G" 위치에 멈춰 설 수 있으며, 이것이 최소 움직임 중 하나입니다.
게임판의 상태를 나타내는 문자열 배열board가 주어졌을 때, 말이 목표위치에 도달하는데 최소 몇 번 이동해야 하는지 return 하는 solution함수를 완성하세요. 만약 목표위치에 도달할 수 없다면 -1을 return 해주세요.
문자열은 ".", "D", "R", "G"로만 구성되어 있으며 각각 빈 공간, 장애물, 로봇의 처음 위치, 목표 지점을 나타냅니다.
"R"과 "G"는 한 번씩 등장합니다.
풀이방법
사용한 알고리즘 : BFS
1. board 와 같은 size인 matrix를 생성하고 99999999로 칸을 채웁니다.
-> 99999999로 되어 있는 칸은 방문하지 않은 칸을 의미합니다.
2. R의 위치를 찾고 deq에 위치를 저장합니다.
3. deq에서 popleft한 요소는 현재 위치를 가리킵니다.
3-1 현재 위치에 G가 있다면 반복문을 탈출하고 현재 cnt를 반환합니다.
4. x, y에 dx[i],dy[i] 를 더해서 다음 위치가 D를 만나지 않거나 좌표 밖으로 나가지 않는다면 더합니다.
5. 만약 좌표 밖이나 D를 만나게 된다면 현재 위치의 cnt + 1 와 matrix에 저장되어있는 수를 비교해서 더 작은 수를 저장합니다.
6. 현재 좌표 nx, ny, cnt + 1 를 deq에 넣고 3번으로 돌아갑니다.
코드
from collections import deque
def solution(board):
answer = 0
N, M = len(board), len(board[0])
deq = deque()
matrix = [[999999999] * M for _ in range(N)]
# R 찾기
for i in range(N):
for j in range(M):
if board[i][j] == 'R':
deq.append((i, j, 0))
matrix[i][j] = 0
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
while deq:
x, y, cnt = deq.popleft()
if board[x][y] == 'G':
return cnt
for i in range(4):
nx = x
ny = y
while 0 <= nx + dx[i] < N and 0 <= ny + dy[i] < M and board[nx + dx[i]][ny + dy[i]] != 'D':
nx += dx[i]
ny += dy[i]
if matrix[nx][ny] > cnt + 1:
matrix[nx][ny] = cnt + 1
deq.append((nx, ny,cnt+1))
return -1
결론
BFS를 이용해서 x, y 에 dx, dy를 더하면서 멈출 때까지 반복하고 cnt를 저장하면 정말 간단하게 풀 수 있는 문제다.
처음에 그래프를 구현할 때 오랜만이라 시간이 걸리기는 했지만 약 1시간을 투자해서 문제를 풀었다. 그래프 문제를 더 열심히 풀어봐야겠다.
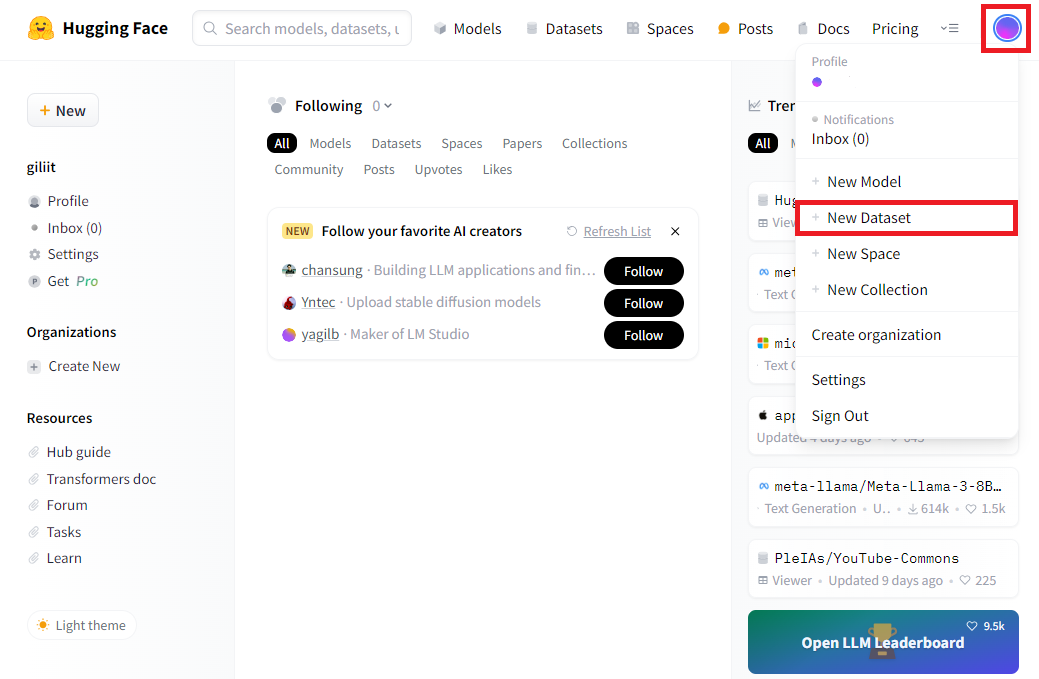
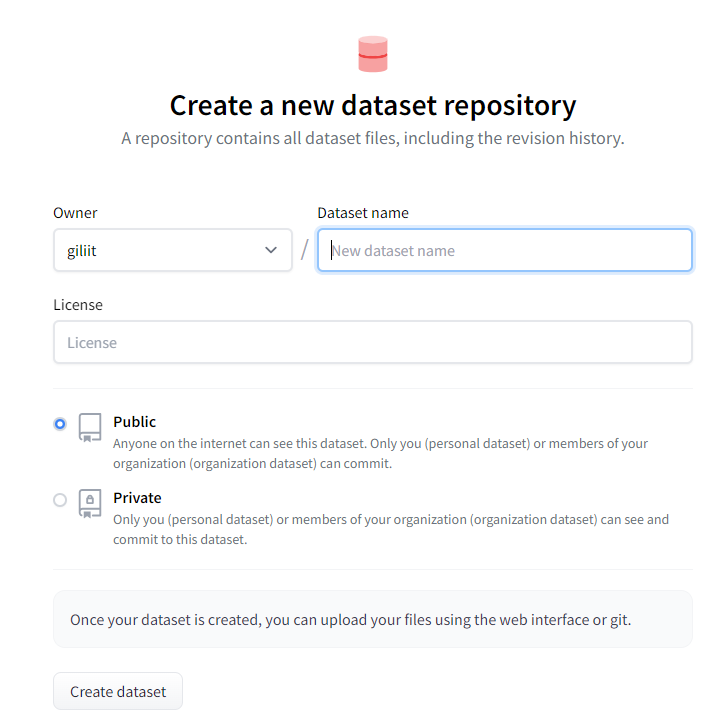
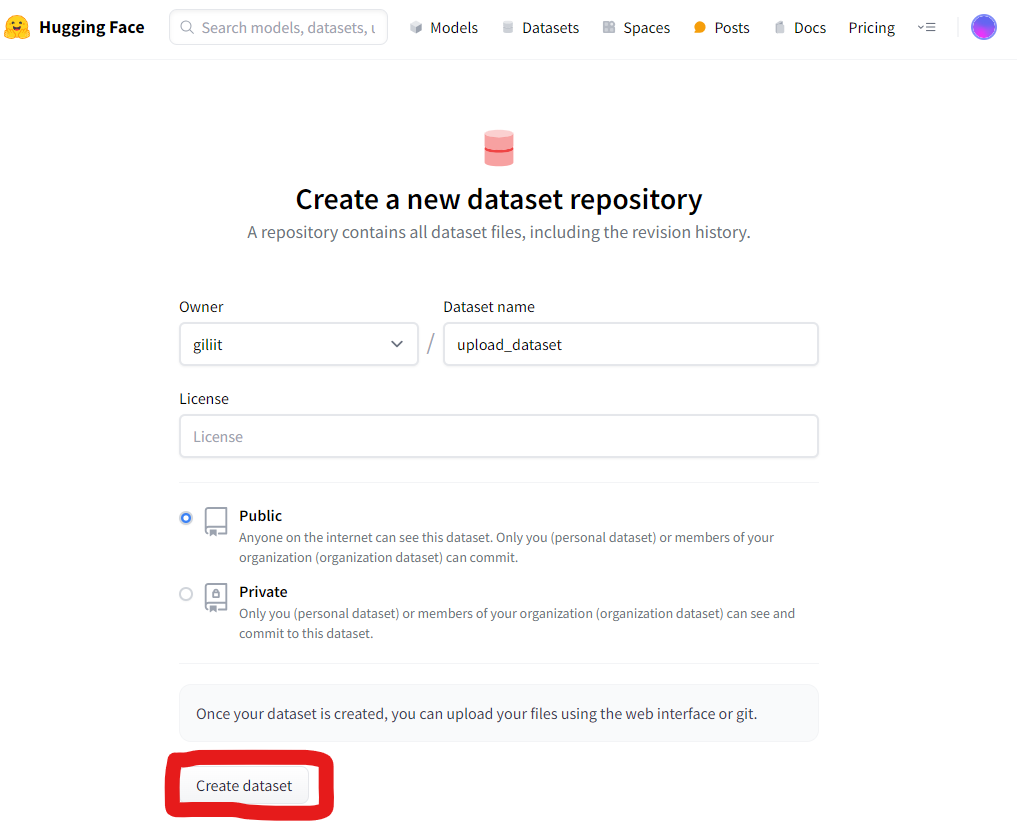
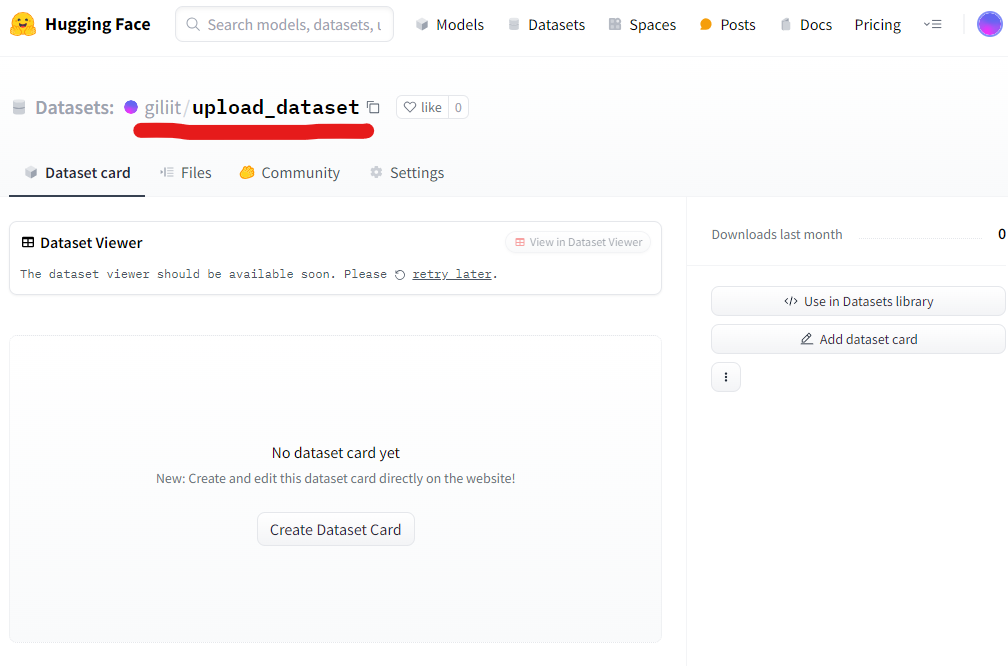
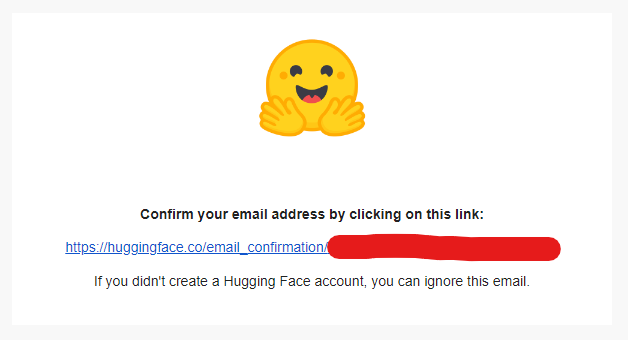
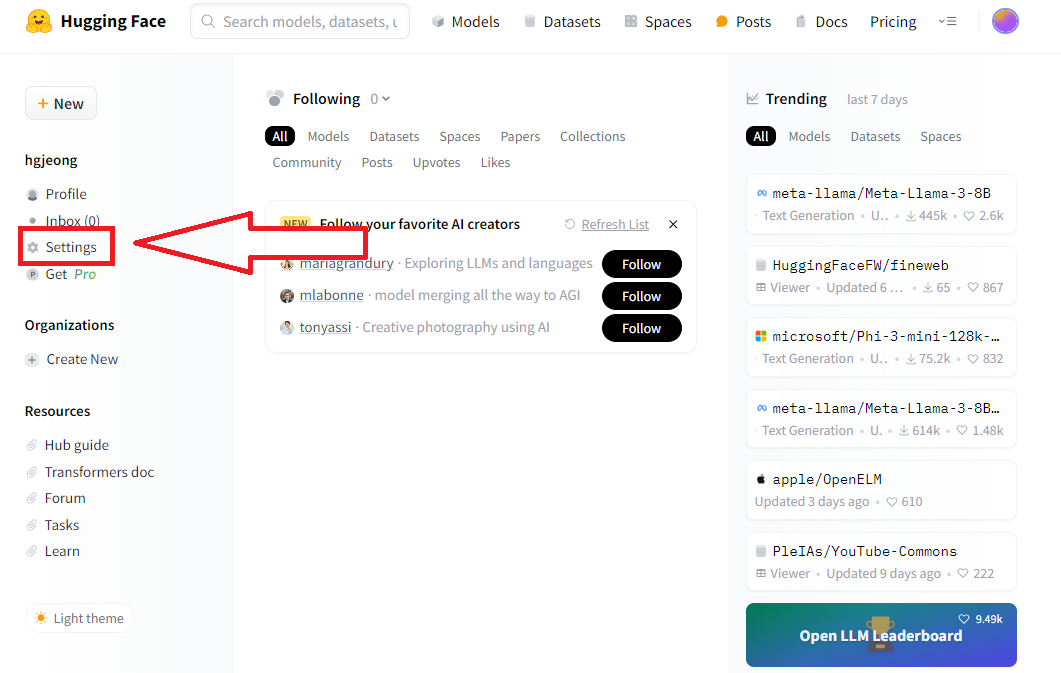
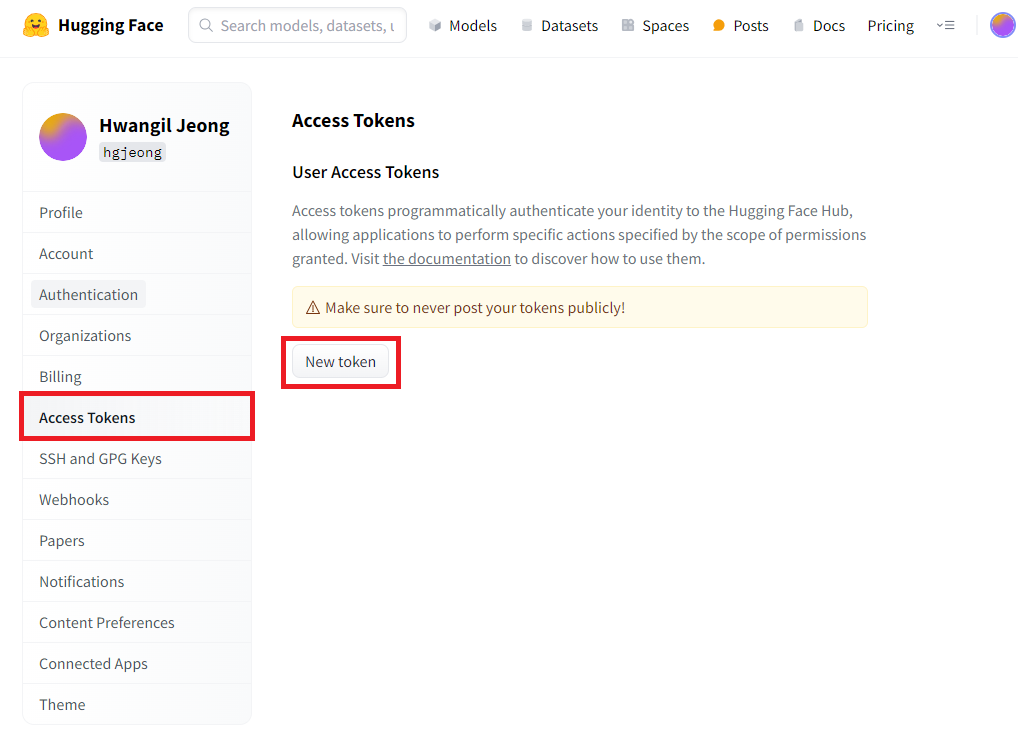
오늘은 허깅페이스에 내가 만든 Dataset을 올리는 방법에 대해 소개해드리려고 합니다. 이를 통해 다른 사람들이 업로드한 데이터셋을 사용할 수 있습니다. Dataset을 업로드하려면 허깅페이스 토큰이 필요합니다. 토큰을 발급받지 않은 분들은 여기를 클릭해서 토큰을 발급해주세요
FastAPI를 공부하면서 pydantic 라이브러리에 대해 알게 되었고, pydantic document를 보게 되면서 공부를 하게되어서 공부하고 깨달은 점에 대해 소개하고자 작성하게 되었습니다.
Pydnatic overview
Pydantic은 Python의 타입 힌트를 활용하여 데이터 유효성 검사와 설정 관리를 자동화하는 강력한 라이브러리입니다. 개발자가 데이터 모델을 정의할 때 명확한 데이터 타입을 지정함으로써, Pydantic은 이 모델을 기반으로 데이터의 유효성을 자동으로 검증합니다. 이 과정에서 데이터 타입의 불일치나 필드의 누락과 같은 문제를 즉각적으로 식별하고 처리할 수 있습니다
다시말하면, 명시해준 데이터 타입과 입력에 대해 data validation을 진행합니다. 이 때, 타입이 다르게 되면 오류를 발생시킵니다. 이와 관련되어 pydantic이 안정되고 특화되어 있고 특히 빨라서 사용합니다.
from datetime import datetime
from pydantic import BaseModel, ValidationError, PositiveInt
class User(BaseModel):
id: int
name: str = 'John Doe'
signup_ts: datetime | None
tastes: dict[str, PositiveInt]
external_data = {'id': 'not an int', 'tastes': {}}
try:
User(**external_data)
except ValidationError as e:
print(e.errors())
"""
[
{
'type': 'int_parsing',
'loc': ('id',),
'msg': 'Input should be a valid integer, unable to parse string as an integer',
'input': 'not an int',
'url': 'https://errors.pydantic.dev/2/v/int_parsing',
},
{
'type': 'missing',
'loc': ('signup_ts',),
'msg': 'Field required',
'input': {'id': 'not an int', 'tastes': {}},
'url': 'https://errors.pydantic.dev/2/v/missing',
},
]
"""
다음은 지정해준 type을 주지 않을때 오류를 발생시킨다. id에서 int형이 아닌 str형을 입력하려고 해서 ValidationError가 발생한다.
type : 오류의 유형을 나타냅니다. int_parsing은 정수 파싱 오류를, missing은 필수 필드가 누락됨을 의미합니다.
loc : 오류가 발생한 모델의 위치를 튜플로 나타냅니다. ('id',)는 id 필드에서 오류가 발생했음을 의미합니다.
msg : 오류의 세부적인 설명을 제공합니다. 예를 들어, Input should be a valid integer, unable to parse string as an integer는 입력이 유효한 정수여야 하며, 문자열을 정수로 파싱할 수 없다는 것을 알려줍니다.
input : 오류가 발생한 때 받은 입력 데이터를 나타냅니다. 'not an int'는 id 필드에 부적절한 입력이 제공되었음을 보여줍니다.
url : 해당 오류 유형에 대한 더 자세한 정보를 제공하는 웹 페이지의 URL입니다.
Validtor Example
field_validator을 이용해서 직접 validtor을 만들 수 있습니다. 다음은 그에 대한 예시입니다.
Field Example
from pydantic import (
BaseModel,
ValidationError,
ValidationInfo,
field_validator,
)
class UserModel(BaseModel):
name: str
id: int
@field_validator('name')
@classmethod
def name_must_contain_space(cls, v: str) -> str:
if ' ' not in v:
raise ValueError('must contain a space')
return v.title()
# 다양한 필드들을 추가할 수 있으며, '*' 기호를 사용하면 모든 필드를 추가할 수 있습니다.
@field_validator('id', 'name')
@classmethod
def check_alphanumeric(cls, v: str, info: ValidationInfo) -> str:
if isinstance(v, str):
# info.field_name is the name of the field being validated
is_alphanumeric = v.replace(' ', '').isalnum()
assert is_alphanumeric, f'{info.field_name} must be alphanumeric'
return v
try:
UserModel(username='scolvin', password1='zxcvbn', password2='zxcvbn2')
except ValidationError as e:
print(e)
"""
1 validation error for UserModel
Value error, passwords do not match [type=value_error, input_value={'username': 'scolvin', '... 'password2': 'zxcvbn2'}, input_type=dict]
"""
@field_validators는 "클래스 메소드"이므로, 받는 첫 번째 인자는 UserModel 인스턴스가 아닌 UserModel 클래스입니다. 정확한 타입 검사를 위해 @field_validator 데코레이터 아래에 @classmethod 데코레이터를 사용하는 것을 추천합니다.
안녕하세요, 오늘은 LLM에서 dictionary를 Chat 형식으로 변환하는 apply_chat_template 함수에 대해 알아보려고 합니다. 이 함수는 최근에 Chat Bot, Chat Model이 많아지면서, Chat 형식으로 변환하는 Tokenizer의 필요로 의해 만들어졌습니다. 그래서 이 함수에 대해 자세히 설명해드리려고 합니다.
선언 방법
사용하는 방법은 쉽습니다. Chat(Dialog)에 대해 apply_chat_template()를 사용하면 바로 출력이 나옵니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-alpha"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, cache_dir='/home/hgjeong/hdd1/hub')
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-alpha"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, cache_dir='/home/hgjeong/hdd1/hub')
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenize 사용 여부
사용하지 않았을 때
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True, return_tensors="pt")
print(tokenized_chat)
### 실행결과
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=False, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
### 실행결과
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
사용했을 때
ㄷtokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
### 실행 결과
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
<| assistant |> 가 추가되어 있는 것을 확인할 수 있습니다.
결론
tokenizer에서 apply_chat_template를 이용해서 Chat(Dialog)를 다음과 같이 간편하게 변환할 수 있습니다. 이를 통해서 Chat(Dialog)를 모델에 입력할 때 다음과 같이 사용할 수 있게 있습니다. 감사합니다.