이번 포스팅에서는 Huggingface hub에서 제공하는 dataset의 목록과 dataset을 불러오는 방법에 대해 알려드리겠습니다.
* 모든 코드는 Jupyter Notebook 환경에서 실행했습니다.
datasets 라이브러리 설치
# Hugging face에서 제공하는 datasets 라이브러리 설치
!pip install datasets
dataset 불러오기
datasets 개수 확인(24.01.03 기준)
import datasets
print(len(datasets.list_datasets()))
# 91305
datasets load 방법(emotions)
from datasets import load_dataset
emotions = load_dataset("emotion")
현재 emotions 안에 train, validation, test 데이터가 각각 16000, 2000, 2000개가 있는 것을 확인할 수 있습니다. 또한, 요소로는 text와 label이 있는 것을 볼 수 있습니다.
그림으로 표현하면 다음과 같습니다.
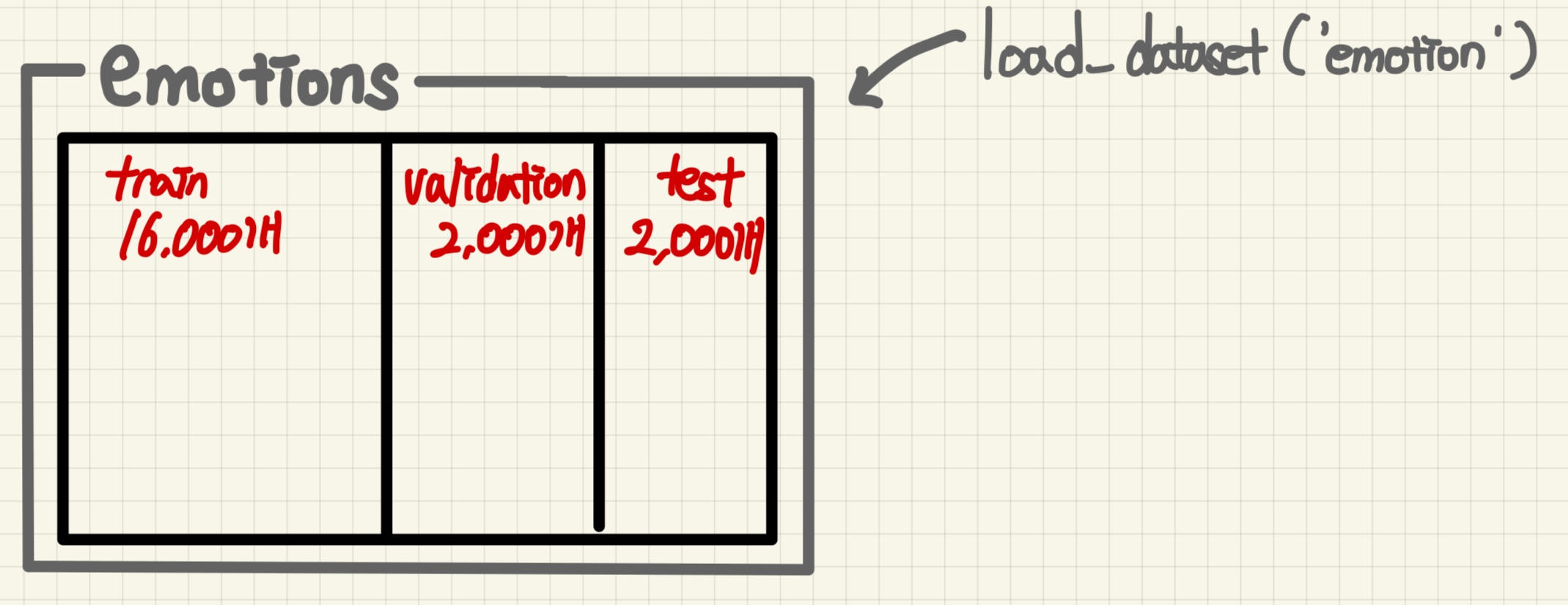
train 내부는 그림과 같습니다.

metrics 불러오기
metrics :자연어 처리에서 모델의 성능을 평가하기 위해 사용되는 수치. 여러 종류의 metrics가 존재하며 각각은 특정 목적에 맞게 설계
- BLEU Score : 모델의 번역 품질을 평가
- ROUGE Score : 모델의 요약 성능을 평가
위와 같은 다양한 metrics가 있으며 불러오는 방법에 대해 설명하겠습니다.
metrics의 목록을 확인
import datasets
print(datasets.list_metrics())
# Output
['accuracy',
'bertscore',
'bleu',
'bleurt',
'brier_score',
'cer',
...
]
metics 중 가장 간단한 accuracy를 사용
from datasets import load_metric
# Accuracy 메트릭 로드
accuracy_metric = load_metric('accuracy')
# 예측된 값과 참조 값
predictions = [0, 1, 1, 0, 1] # 예측된 레이블 예시
references = [0, 1, 0, 0, 1] # 실제 레이블 예시
# Accuracy 스코어 계산
results = accuracy_metric.compute(predictions=predictions, references=references)
print(results["accuracy"])
# Output
# 0.8
metrics 중 bleu사용
from datasets import load_metric
# BLEU 메트릭 로드
bleu_metric = load_metric('bleu')
# 예측된 번역과 참조 번역
predictions = [["the", "cat", "is", "on", "the", "mat"]]
references = [[["the", "cat", "is", "on", "the", "mat"]]]
# BLEU 스코어 계산
results = bleu_metric.compute(predictions=predictions, references=references)
print(results["bleu"])
# Output : 1.0
Hugging face의 dataset과 metrics의 목록과 사용법에 대해 알아봤습니다. 다음엔 모델에 사용하는 방법에 대해 알아보겠습니다.
'AI & DL > Hugging Face' 카테고리의 다른 글
| [Hugging Face] 모델 가져오기(Read), 모델 및 데이터 업로드(Write)를 위한 Token 발급 받는 방법 (1) | 2024.04.28 |
|---|---|
| [Hugging Face] apply_chat_template 함수에 대해 알아보자 (0) | 2024.04.20 |
| [Hugging Face] 벤치마크 클래스 만들기 ( Benchmark Class) (0) | 2024.01.16 |
| [Hugging Face] Dataset의 map 함수 사용법 (1) | 2024.01.14 |
| [Hugging Face] evaluate.evaluator을 이용하여 모델 평가하기 (1) | 2024.01.04 |