최근에 동아리에서 구현해야 할 기술에 대해 고민을 하고 있는데 범위가 상당하다 보니 데이터를 만들어서 진행하는 것은 어렵다고 판단했다. 그래서 데이터베이스에서 가져오는 방법을 고민하고 있으며 그중에서 NAACL에 대해서 찾아보다가 알게 되어서 논문을 읽어보았다.
논문링크
https://arxiv.org/pdf/2406.12430
Introduction
현실세계에서 사업과 관련된 상황에서 결정을 하는 것은 매우 중요한 일이다. 결정을 하기 위해서는 데이터 분석을 통해 가장 적절한 결정을 해서 목표를 달성하는 것이다. 일반적으로 결정을 하는 일은 3가지 과정을 요구한다.
- 결정에 필요한 데이터들을 분석하여 계획을 세운다.
- 관련된 필수적인 데이터를 검색한다.
- 데이터를 기반으로하여 걸 정한다.
여기서 2번과 3번 과정을 쉽게 하기 위해, 지난 몇 십 년간 결정을 도와주는 시스템을 구축했다. 하지만, 1번 단계는 사람이 도맡아서 하고 있다. 그래서 이 논문에서는 Large Language Model(LLM)을 이용해서 end-to-end 시스템을 구축한다.
이 시스템 구축을 위해 Decision QA 데이터를 구축했다. 이 데이터는 Language Model(LM)이 의사결정을 하도록 하는 데이터셋이다. 관련 내용은 아래에 자세하게 설명하겠다.
마지막으로 (1) 번 단계를 LM이 실행할 수 있도록 하는 것이 Retrieval Augmented Generation(RAG) 방식이었는데, 이전의 방식은 단일 정보만을 가져오는 방식보다는 보다 의사결정을 잘할 수 있는 plan-then-retrieval augmented generation technique, PlanRAG 방식을 구축했다. 간단하게 설명하면 3단계로 구성된다.
- the planning step : 분석을 위해 필요한 정보들을 가져오는 데이터 스키마와 질문들을 생성한다.
- the retrieving step : 분석을 위한 데이터를 검색
- the answering step : 데이터를 기반으로 하여 결정하기
이에 대해서도 아래에 자세하게 설명하려고 한다. 논문의 기여는 다음과 같다.
- Decision QA를 위한 벤치마크인 DQA를 제안한다.
- PlanRAG라는 새로운 검색-증강 생성 기술을 제안하며, 이는 LLM(대형 언어 모델)의 의사 결정 능력을 크게 향상할 수 있다.
- PlanRAG가 Decision QA에서 반복적인 RAG 기술보다 훨씬 효과적이라는 것을 입증했다.
About Decision QA(DQA)
Dataset
데이터는 무역 데이터를 기반으로 작성되었다. 무역 게임은 Enropa Universalis IV와 Victoria 3을 기반으로 데이터를 만들었다. 무역게임으로 만든 이유는 현실의 데이터는 구성하기 힘들기 때문이며, 이와 비슷한 무역게임으로 구성했다.
- $d_{best}$ : 가장 좋은 결정
- $Q$ : 의사결정과 관련된 질문
- $D$ : Database
- $R$ : Business Rule
위의 데이터를 이용해서 가장 이득을 취할 수 있는 방법을 찾는 것이다.
데이터베이스 형식은 2가지로 되어있다. Labeled Property Graph(LPG)(=Graph Database, GDB)와 Relational Database(RDB)로 구성되어 있다.

각각 301개씩 총 602개로 구성되어 있다.
Benchmark
Locating Scenario
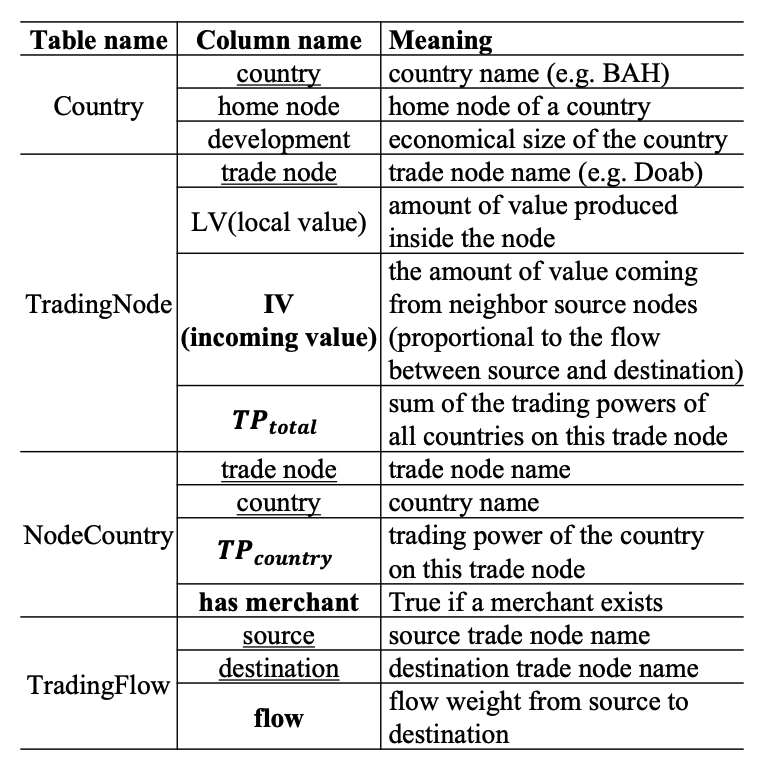
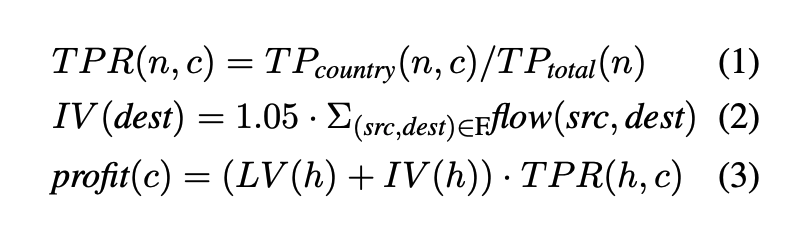
- 이 시나리오의 데이터베이스는 4개의 테이블로 구성되어 있다.
- 트레이딩플로우와 노드국가는 간선, 트레이딩노드와 국가는 정점으로 그래프 데이터베이스로 표현할 수 있다.
- 비즈니스 규칙에 따라 열 값이 다른 데이터와 사용자 결정으로 계산된다.
- 사용자가 트레이딩 노드에 상인을 배치하면, 그 노드에서 해당 국가의 홈 노드로 흐름이 증가한다.
- 주요 변수는 국가(c), 트레이딩 노드(n), 출발 노드(src), 목적지 노드(dest), 홈 노드(h)이다.
- 목표는 ∆profit(c)를 최대화할 수 있는 트레이딩 노드를 선택하는 것이다.
Building Scenario


- 이 시나리오에서 데이터베이스 D는 관계형 데이터베이스(RDB) 일 때 4개의 테이블로 구성된다.
- Demand와 Supply는 간선, Goods와 Buildings는 정점으로 간주하여 그래프 데이터베이스(GDB)로 쉽게 표현할 수 있다.
- 기본적인 비즈니스 규칙은 의사 결정자가 공장 건물 b를 확장하면, 해당 상품 g의 CO(g, b)가 증가한다는 것이다.
- 주요 변수는 상품(g)과 건물(b)이다.
- Supply 집합을 Sup, Demand 집합을 Dem으로 나타내며, T D는 총 수요, T S는 총공급을 의미한다.
- 목표는 주어진 상품 g에 대해 CP(g)를 최소화하는 것이다.
About Plan-RAG
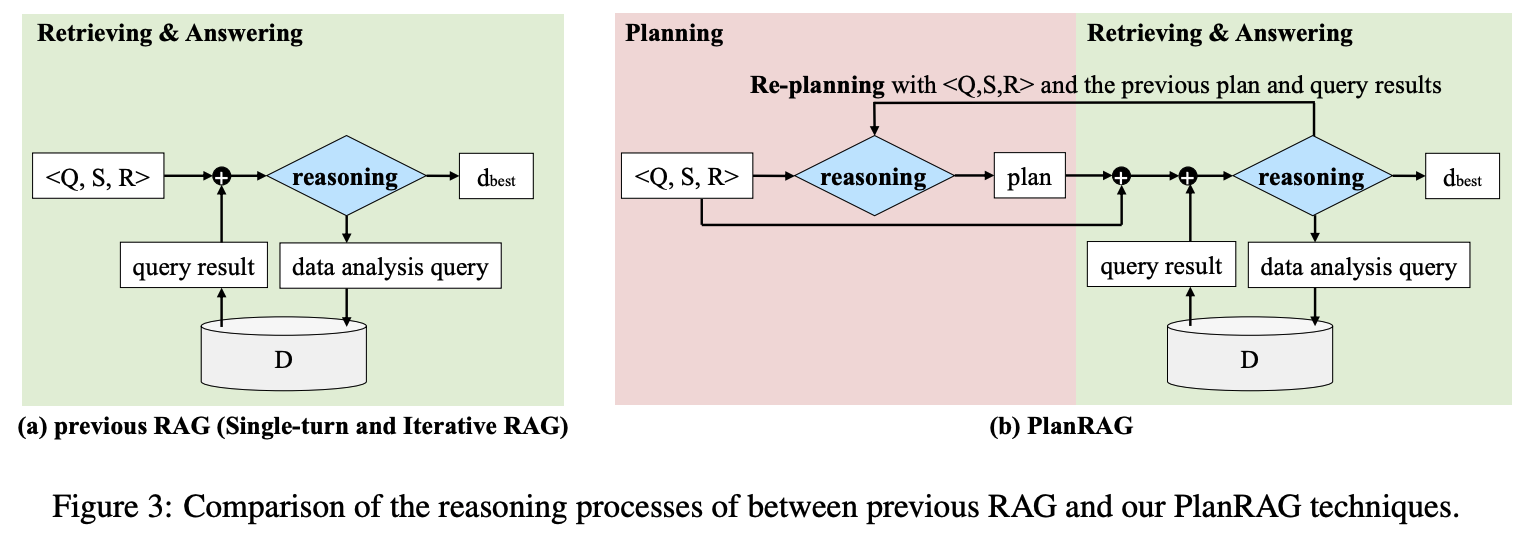
기존 RAG 기술은 데이터 분석 쿼리를 사용하여 데이터베이스 D에서 검색된 결과를 기반으로 주어진 ⟨Q, S, R⟩에 대한 최적의 결정을 도출하려고 한다. 한 번만 검색이 이루어지면 이를 단일 회차 RAG(single-turn RAG)라고 하며, 여러 번 검색이 이루어지면 반복 RAG(iterative RAG)라고 한다. PlanRAG 기술은 두 가지 유형의 추론을 사용하여 최적의 결정을 도출하려고 한다.
첫 번째는 계획 수립, 두 번째는 기존 RAG와 유사한 방식으로, 데이터 분석 쿼리를 통해 검색된 결과를 바탕으로 답변하는 것이다. PlanRAG는 계획과 재계획을 수행할 수 있는 단일 언어 모델을 사용하여, 별도의 모델을 사용하는 부작용을 줄였다. 이 모델은 ReAct(Yao et al., 2023)의 'Plan'과 'Re-plan' 지시문을 추가하여 프롬프트를 작성했다.
PlanRAG의 추론 과정은 (1) Planning, (2) Retrieving & Answering, (3) Re-planning의 단계를 포함한다.
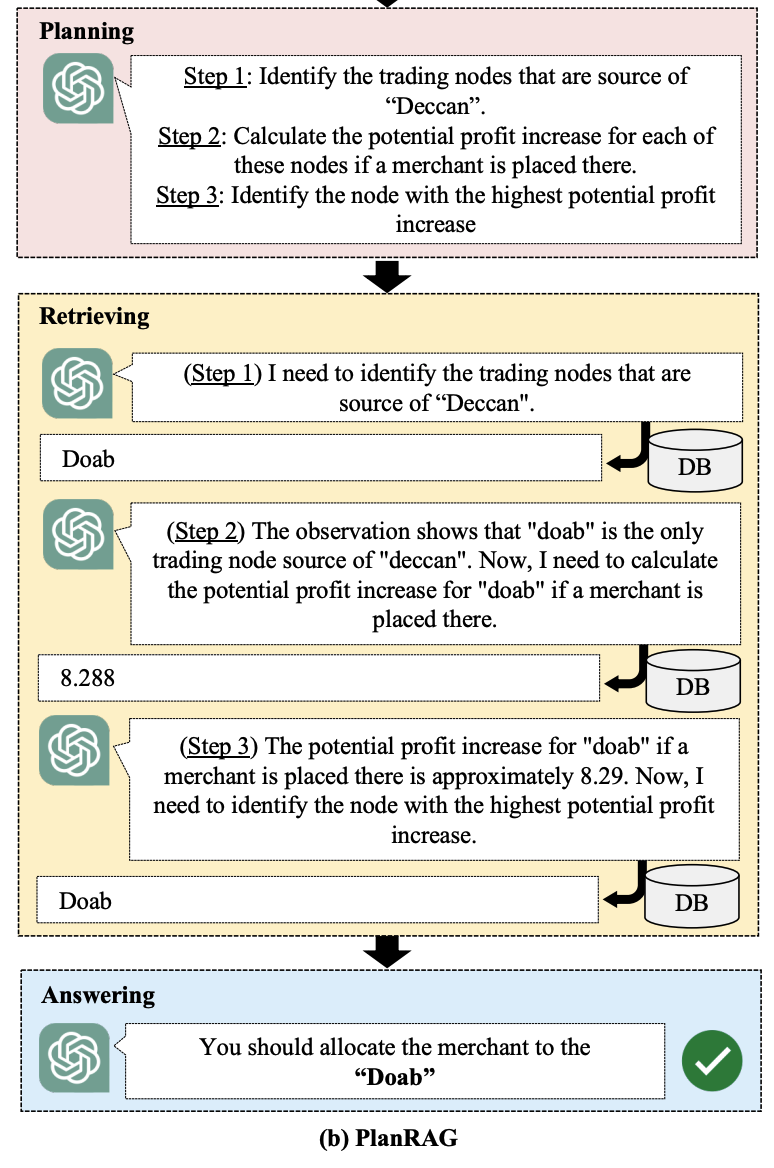
Planning
LM이 입력으로 ⟨Q, S, R⟩가 주어지며 데이터 분석을 위한 초기의 계획을 생성한다. 초기 계획은 검색 절차에서 수행에 필요한 일련의 데이터들을 계획하는 것이다.
Retrieving & Answering
이전 RAG과 달리 ⟨Q, S, R⟩뿐만 아니라 초기 계획도 가치 입력된다.
Re-planning
초기에 세워진 계획이 문제 해결에 충분하지 않다고 생각이 되면 다시 계획하여 필요한 정보들을 더 가져오는 방식이다.
Experiments
Experimental Setup
모델들은 다음과 같다.
- SingleRAG-LM → Single-turnLM
- IterRAG-LM → Iterative RAG
- PlanRG-LM → PlanRAG
- PlanRG-LM w/o RP(Re-Planning)
모든 결정은 GPT-4로 생성되었으며 temperature = 0 그리고 LangCahin library로 구성되어 있다. 모든 실험은 0-shot으로 진행했는데 그 이유는 few-shot의 경우는 모델의 오버피팅을 야기하며, 현실에서는 예시가 주어지지 않기 때문이다.
Results & Analysis
Main Results

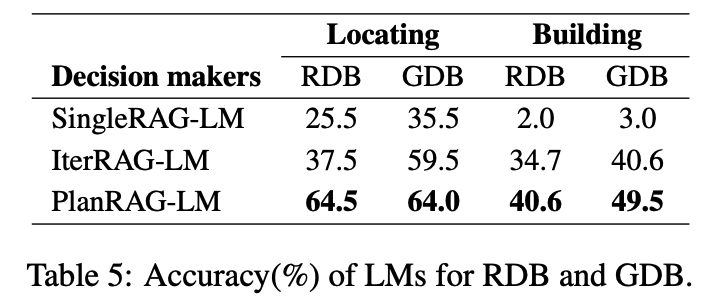
여기서 계획한 PlanRAG가 SOTA를 달성했으며, 표를 통한 결과는 다음과 같다.
- Building score이 낮은 이유 : Building Scenario는 Location에 비해 더욱 긴 traversal을 요구하기 때문에 낮은 점수가 나왔다.
- SingleRAG-LM이 낮은 이유 : 여기서 제시하는 문제들은 여러 turn을 요구하기 때문에 낮은 점수가 나왔다.
- RP의 효과 : 다시 계획하는 것을 통해 PlanRAG-LM이 가장 좋은 점수를 달성하였다.
Analysis for SR and MR
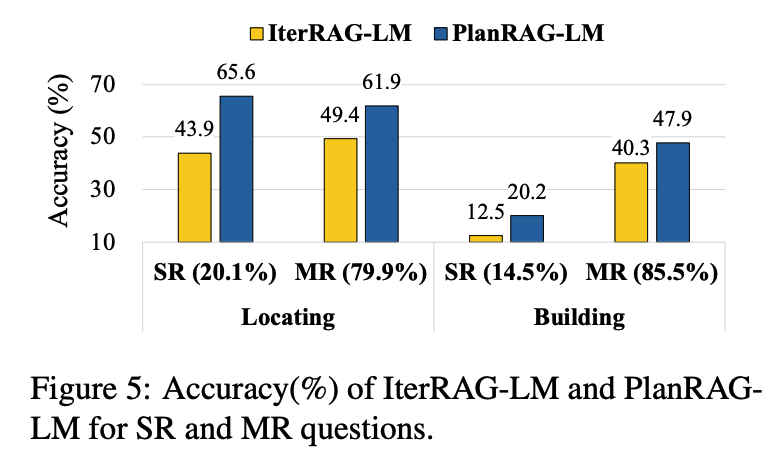
데이터의 난이도에 따라 얼마나 문제를 잘 해결하는지에 대해 탐구했다. IterRAG-LM이 문제 해결을 위해 검색을 얼마나 했는지에 따라 데이터는 2가지로 나누었다. Single Retrieval, SR : 정보 검색을 한 번만 한 것(84개). 정보 검색이 쉬운 것이며 Multiple Retrieval, MR : 정보 검색을 여러 번 한 것(518개). 정보 검색이 어려운 것이다.
- PlanRAG-LM은 SR 질문에서 IterRAG-LM보다 훨씬 더 우수한 성능 : SR 질문들이 단일 검색으로는 해결하기 어려운 경우가 많기 때문이다.
- IterRAG-LM은 이러한 질문들의 난이도를 과소평가하여 단일 검색만 사용하려 했지만, 실제로는 여러 번의 검색이 필요한 경우가 많았다.
- PlanRAG-LM은 계획 단계를 통해 질문의 난이도를 더 잘 이해하고, 계획에 따라 여러 번 검색을 수행하여 정확성을 크게 향상했다. MR 질문에서도 PlanRAG-LM이 더 체계적으로 검색을 수행하여 IterRAG-LM보다 더 효과적이다.
Rate of missed data analysis

PlanRAG-LM은 IterRAG-LM보다 더 효과적인 이유를 분석하기 위해 데이터 분석 누락 비율을 측정했다. Locating에서는 IV와 T Ptotal, Building에서는 CO와 PD를 기준으로 사용했다.
- PlanRAG-LM의 누락 비율은 1.3%와 21.8%로 낮았고, IterRAG-LM은 3.3%와 33.2%로 더 높았다. 이는 IterRAG-LM이 완벽하게 추론을 수행하더라도 정확도가 PlanRAG-LM보다 낮을 가능성이 있음을 의미한다.
- PlanRAG-LM은 Locating에서 98.7%의 정확도를 달성할 수 있지만, 실제 정확도는 그보다 낮았으며, 이는 추론(계획 포함) 자체가 매우 도전적인 작업이기 때문이다.
Analysis for failure cases

우리는 각 실패 사례를 다섯 가지 오류 카테고리로 분류한다:
- CAN: 잘못된 후보를 고려하여 질문을 해결하지 못한 경우
- MIS: 데이터 분석 누락
- DEEP: 검색된 데이터나 방정식을 잘못 사용한 경우
- QUR: 쿼리 생성 오류
- OTH: 기타 오류 (예: 토큰 길이 제한 초과)
PlanRAG-LM은 두 시나리오 모두에서 CAN과 MIS 오류를 크게 줄였다. 이는 PlanRAG-LM이 Decision QA 질문을 더 잘 이해하고, IterRAG-LM보다 중요한 데이터를 더 잘 쿼리 할 수 있음을 의미한다. 또한, PlanRAG-LM이 두 시나리오 모두에서 IterRAG-LM보다 약간 더 많은 DEEP 사례를 가지고 있음을 주목할 수 있다. 우리의 관찰에 따르면, DEEP 오류는 CAN 또는 MIS 오류가 없을 때만 발생한다.
Anylsis for re-planning

PlanRAG-LM은 Locating 시나리오보다 Building 시나리오에서 재계획을 더 자주 수행한다. 네 번 이상 재계획이 이루어진 질문의 비율은 Building에서 훨씬 높다(30개 질문, 14.85%)가 Locating에서는 7개(1.75%)에 불과하다. 이는 원래 계획이 불충분할 경우 모델이 재계획을 수행한다는 것을 의미하며, 이는 Building에서 PlanRAG-LM과 다른 기술들 간의 성능 차이가 상대적으로 적은 이유를 설명한다. 또한, 재계획 횟수가 많아질수록 재계획으로 인해 향상되는 정확도가 감소한다는 Table 7의 결과와 일치한다.
Conclusion
복잡한 의사 결정 질문에 답하는 새로운 과제인 Decision QA를 제안했다. 이를 위해 DQA라는 벤치마크를 만들었으며, 301개의 데이터베이스 세트와 질문, 정답을 사용하여 구성했다. 또한, 검색 전에 계획을 세우고 계획이 충분하지 않을 경우 재계획을 수행하는 PlanRAG라는 새로운 RAG 기술을 제안했다