논문링크
https://arxiv.org/abs/2406.10960
Intoduction
Emotional Support(ES)는 care, concern, affection, interests, indiviauls feeling 등을 개념화하는 것이다. Emotional Support Conversation(ESC)는 Seeker에게 좋은 영향을 주는 것이다. 최근 연구되고 있는 ESC와 관련해서 매우 효능이 있는 Service이다. 하지만 이와 관련하여 LLM을 이용한 dialogue는 블랙박스이며, 왜 그러한 반응들을 산출했는지에 대해 알 수 없다. 그래서 ES에 대해서 dialogue등이 나오게 되는 과정을 Chain-of-Thought(CoT)방식으로 작성을 하면, 더욱 좋은 성능을 발휘할 것이라고 생각한다. 과정은 이렇게 시작한다.
- seeker의 감정과 상황에 대해 파악한다.
- emotion에 대해 이해한다.
- 적절한 strategy를 선택하며, 그 이유에 대해 서술한다.
이러한 방식을 사용하면, 신뢰할 수 있을 것이며, 좋은 대답을 나올것이라 기대하고 있다. 또한, CoT를 사용하는 이유들로는 그전에 ESC 관련 dataset은 CoT방식을 사용하지 않았기 때문이며, 비용이 매우 값비싸기 때문이다. 그래서 LLMs을 이용하여 CoT 과정을 만들도록 한다.
이 논문을 통한 기여는 다음과 같다.
- Emotional support response generation의 해석에 대해 신뢰성을 증가하기 위해 strategy가 선택된 이유에 대해 CoT를 만들었다.
- CoT를 포함한 첫번째 데이터셋이다.
- 데이터셋을 검증하기 위해 human evaluation을 적용했다.
- 첫CoT 데이터셋이므로 이후 연구에 대해 baseline을 제공한다.
ESD-COT Dataset Construction
데이터셋 생성과정은 다음과 같다.
- ESD Contruction : ES와 관련한 다양한 situation을 생성하고 더 많은 전략을 이용해 dialogue를 생성한다.
- ESD-CoT Construction : 먼저 생성한 dialogue에 대해 왜 그러한 전략을 선택했는지 CoT를 생성하고 CoT가 잘 생성되었는지 수동적으로 검증을 한다.( 유효성을 보증하기 위해서)
ESD Construction
여기서 situation- and strategy-guided dialogue generation scheme을 제시한다. 이를 통해 a situation-diverse, strategy-rich Emotional Support Dialogue dataset(ESD)를 생성한다.
처음에 situation과 enrich startegies를 생성하기 위해 기본적으로 ESConv Dataset을 사용한다. 이를 이용해 생성 가이드라인을 만들 수 있다.
Situation Generation
LLM의 In-context learning method + ESConv Dataset의 다양한 situation을 이용하여 더욱 많은 situation을 생성한다.

생성 Format은 다음과 같고 여기서 8개는 ESConv Dataset에서 선택을 하고 나머지 8개는 생성하도록 한다. 그럼 어떻게 선택되는 것인가? 약 1,300개의 situation 중에서 임의적으로 8개를 선택한다.이 때, 부적절한 상황이다. 불완전한 문장은 삭제하도록 한다.
이러한 방식을 이용해 2,943개의 new situation을 생성하였다.
Strategy Enrichment
ESConv Dataset에서는 8개의 전략이 선택되었다. 이 데이터셋에서는 중요한 전략들도 Other로 포함시켜버렸기 때문에 이 논문에서는 더 많은 전략을 사용하려고 한다. 전략은 3가지 기준에 따라서 추가하도록 했다.
- Distinct : 이미 존재하는 전략과 구별되어 뚜렷한가
- Understandable : 짧은 설명으로 간결하게 설명하여 이해할 수 있는가
- Identifible : 이미 존재하는 전략과 구별이 가능한가
3가지 전략을 이용해 6가지 전략을 추가했다.
- Summarize : 전체 대화를 요약 (vs Restatement or Paraprasing : 간단히 언급한것에 대해서만 요약)
- Homework Assignment : 직접적으로 seeker가 무엇을 해야하는지 제시 ( vs Providing Suggestions : 간접적으로 seeker이 하는 것을 제시)
- Imagery
- Specify
- Take Responsibility
- Immediacy
Dialogue Generation
situation + strategies를 이용하여 Dialouge를 생성하도록 했다.
여기서 3가지 Part로 나뉘게 된다.
- Description : task와 therapist의 역할에 대해 소개한다.
- Reference : Reference Situation, Reference Dialogue : 특정 Situation과 그에 대해 성생된 Dialogue에 대해 예시를 제시한다. 이를통해 ChatGPT가 생성하도록 format을 만든다.
- Instruction : Target Situation과 Enriched Stratgies에 대해 언급을 하고서, Task에 대해 다시 언급을 하고서 Dialogue를 생성하도록 지시한다.
Filtering and Postprocessing
생성된 대화 중에서 불완전한 데이터는 4가지 종류로 나뉜다.
- 부적절한 상호작용 dialogues
- 빈 발언의 존재
- 불충분한 전략 주석
- 전략과 발화의 불일치
이러한 문제를 해결하기 위해서 수작업으로 모드 filtering을 진행하였다.
Statistics of ESD
ESD Dataset의 질을 높여서 생성된 결과는 다음과 같다.
Diversity of Analysis
Situation Diversity에 대해 조사를 하였다. 여기서는 각 상황에 대해 자주 나오는 단어들에 조사를 하였다. 예를 들자면, 건강 문제에 대해서는 PTSD, Depression과 관련된 단어가 많이 나오는 것이다. 이에 대해 조사를 하였고, 다음은 그에 대한 그림이다.

Strategy Analysis
여기서는 Strategy의 사용 빈도에 조사하였는데, 새롭게 추가된 전략도 매우 자주 사용하는 것을 확인할 수 있다.

ESD-CoT Construction
모델의 해석력 부족은 모델에 대핸 사람의 신뢰에 영향을 미치기에 모델의 해석력을 높이는 것이 중요하다. 그래서 논문에서는 Emotional-focused and Strategy-driven Chain-of-Thought (ESCoT)를 제안한다. 이것은 사람의 상담 과정을 흉내내며, 전략과 그에 따른 응답을 선택하는 과정을 CoT 형식으로 Dataset이 구성되어 있다. CoT를 생성하기 위해서 총 5가지 과정을 이용한다.
Chain Creation
- Emotion (EM) : seeker의 감정을 파악한다.
- Emotion Stimulus (ES) : seeker의 감정의 원인에 대해 파악한다.
- Individual Appraisal (AI) : 과거 경험을 토대로 seeker의 감정 자극 요소에 대해 평가한다.
- Strategy Reason (SR) : 왜 그러한 전략을 선택했는지 이유에 대해 파악한다.
- Response (RE) : 진행되고 있는 대화에 대해서 반응을 생성한다.

Manual Correction
데이터를 생성하고서 오류에 대해 파악을 하고 filtering을 진행했다. 생성된 데이터셋은 4가지로 오류가 있었다.
- 특정 예시 부족
- 명확하지 않은 감정 표현
- 사람에 대핸 장황한 평가
- 전략과 반응의 불일치
이러한 오류에 대해 이상한 데이터는 제거하여서 총 1,708개의 CoT를 얻었다.
Statistic of ESD-CoT
생성된 데이터셋에 대한 통계를 설명한다. 첫번째로는 발 화의 길이이다.

여기서 나타나는 특징은 다음과 같다.
- EM은 감정에 대해 정의하므로 길이가 짧다.
- IA는 ES보다 약 2배 정도 길다. 그 이유는 ES 내용에 대해 더욱 세세하게 서술한 것이 IA이다.
- SR은 전략에 대해 추론한 과정을 설명하기에 매우 길다.
결과적으로 CoT가 모델의 해석력을 뒷받침해준다.

전략 선택에 대한 분포는 다음과 같은데 각 전략에 대해 최소 100개씩 포함되도록 하여 퍼져있지만, 특히 Affirmation and Reassurance(AR)와 Probiding Suggestions(PS)가 가장 많이 분포해있다.

빈도에 대해 파악을 했는데 각 Figure에 대해 설명한다.
- Emotion : seeker의 감정으로 overwhelmed, uncertain, stressed가 많이 분포하고 있다.
- Emotional Stimulus : job, life, partner 관련 단어가 가장 많이 포함하고 있어 타케팅된 도움을 제공할 수 있다.
- Individual appraisal : unsure, lack이 자주 나타나는 것으로 자신의 상황과 관련해 job, life, partner과 관계에 대해 어려움을 겪고 있는 것을 알 수 있다.
- Strategy Reason : provide, support, acknowledge가 많이 나타나는 것을 통해 supporter가 전략을 선택할 때, 무엇을 최우선으로 생각하는지에 대해 알 수 있다.
이러한 제안은 ES를 통해 seeker의 불안감을 완화하고 감정을 이해하도록 한다.
Experiments
실험 데이터셋은 train, valid, test를 각각 7:1:2 비율로 나누어서 진행하였다. 모델로는 3가지를 이용했다.
- BlenderBot
- DialoGPT
- LLAMA2-Chat
Pre-trained Model을 이용하여 진행했다.
Metric
여기서 autmatic metirc(BLEU-n, ROUGE-L, Distinc-n)과 human eval(Coherence, Informativeness, Empathy, Accuracy) 2가지로 평가하였다.
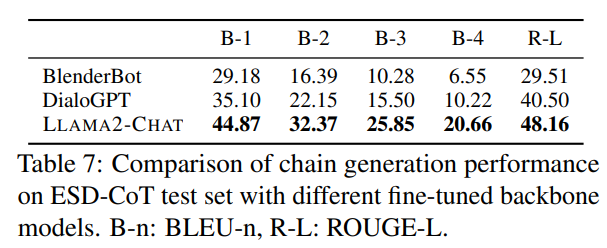
Table 5은 실험결과이며 여기서 알 수 있는 것은 다음과 같다. LLaMA 2가 가장 좋은 성능을 나타내며, Parameter수가 증가할수록 좋은 성능을 나타낸다.
위의 성능을 바탕으로 LLaMA2를 이용해 실험을 진행했다.

Table 6을 통해 알 수 있는 실험결과는 다음과 같다.
B-n, R-L에서는 RE를 제외하고 나머지를 제거한 것이 좋은 성능을 나타냈는데 이것은 RE를 바탕으로 답변을 하다보니 다양한 답변을 하기보다는 제한된 답변을 한다( ES에서는 좋은 것이 아님)
그리고 모든 것을 포함하고 있는 모델(row 1)에서는 D-1, D-2 그리고 Human Evaluation에서 가장 좋은 성능을 타나냈다. 이것은 CoT 역할이 매우 좋고 중요하다는 것을 알 수 있다.
Conclusion
이 데이터셋이 매우 괜찮다고 생각하는 이유는 이전에 모델은 그저 전략 선택했을 뿐, 전략을 왜 선택하는지에 대해서는 언급이 없었다. 단지 데이터셋을 만들고 증강하는 기법에 대해서만 소개했다. 하지만 이 논문에서 아쉬운 점은 데이터셋을 구성할 때, 좀 더 체계적으로 했으면 좋겠다. 단어의 분포를 나타내는 것이나 데이터셋 평가에 대해서도 이전에서 나오는 논문 Figure가 아니어서 많이 낯설게 느껴졌다. 아직 Accepted 논문이 아니므로 수정되거나 발전될 것이라고 생각한다.